
Amazon Web Services (AWS)
What is AWS?
AWS (Amazon Web Services) is a comprehensive, evolving cloud computing platform provided by Amazon. It includes a mixture of infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS) and packaged software-as-a-service (SaaS) offerings. AWS offers tools such as compute power, database storage and content delivery services.
Amazon.com Web Services launched its first web services in 2002 from the internal infrastructure that the company built to handle its online retail operations. In 2006, it began offering its defining IaaS services. AWS was one of the first companies to introduce a pay-as-you-go cloud computing model that scales to provide users with compute, storage and throughput as needed.
AWS offers many different tools and products for enterprises and software developers in 245 countries and territories. Government agencies, education institutions, nonprofits and private organizations use AWS services.
Why is AWS important?
With more than 200 services, AWS provides a range of offerings for individuals, as well as public and private sector organizations to create applications and information services of all kinds. The services are cloud-based and tend to be cost-effective. They interact with many programming languages, communicate over many different networks and interface with competing cloud service providers (CSPs).
AWS was the first developer of cloud-based services, and, as a result, has a large inventory of offerings and customer base. It's used by organizations around the world via its global network of data centers.
How AWS works
AWS is separated into different services; each can be configured in different ways based on the user's needs. Users can see configuration options and individual server maps for an AWS service.
The AWS portfolio includes the following categories of services:
- Compute.
- Storage.
- Databases.
- Infrastructure management.
- Application development.
- Data management.
- Migration.
- Hybrid cloud.
- Networking.
- Development tools.
- Management.
- Monitoring.
- Security.
- Governance.
- Big data management.
- Analytics.
- Artificial intelligence (AI).
- Mobile development.
- Messages and notifications.
Availability
AWS provides services from dozens of data centers spread across 105 availability zones (AZes) in regions across the world. An AZ is a location that contains multiple physical data centers. A region is a collection of AZes in geographic proximity connected by low-latency network links.
A business will choose one or multiple AZes for a variety of reasons, including compliance, proximity to customers and availability optimization. For example, an AWS customer can spin up virtual machines and replicate data in different AZes to achieve a highly reliable, cost-effective cloud infrastructure with scalability that's resistant to the failure of individual servers and an entire data center.
Amazon Elastic Compute Cloud (EC2) is a service that provides virtual servers -- called EC2 instances -- for compute capacity. The EC2 service offers dozens of instance types with varying capacities and sizes. These are tailored to specific workload types, use cases and applications, such as memory-intensive and accelerated-computing jobs. AWS also provides Auto Scaling, a tool to dynamically scale capacity to maintain instance health and performance.
Storage
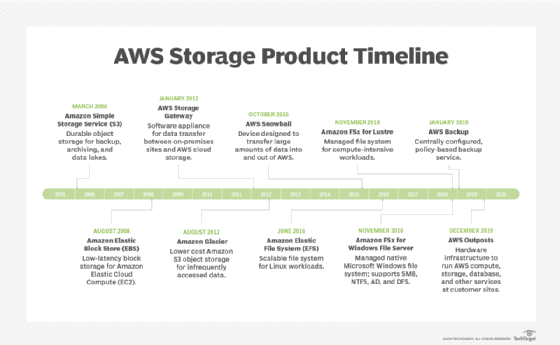
Amazon Simple Storage Service (S3) provides scalable object storage for data backup, collection and analytics. An IT professional stores data and files as S3 objects -- which can range up to five terabytes -- inside S3 buckets to keep them organized. A business can save money with S3 through its Infrequent Access storage class or by using Amazon Glacier for long-term cold storage.
Amazon Elastic Block Store provides block-level storage volumes for persistent data storage when using EC2 instances. Amazon Elastic File System offers managed cloud-based file storage.
A business can also migrate data to the cloud via storage transport devices, such as AWS Snowball, Snowball Edge and Snowmobile, or use AWS Storage Gateway to let on-premises apps access cloud data.
Databases and data management
The Amazon Relational Database Service includes options for MariaDB, MySQL, Oracle, PostgreSQL, SQL Server and a proprietary high-performance database called Amazon Aurora. It provides a relational database management system for AWS users. AWS also offers managed NoSQL databases through Amazon DynamoDB.
An AWS customer can use Amazon ElastiCache and DynamoDB Accelerator as in-memory and real-time data caches for applications. Amazon Redshift offers a data warehouse, which makes it easier for data analysts to perform business intelligence tasks.
Migration and hybrid cloud
AWS includes various tools and services designed to help users migrate applications, databases, servers and data onto its public cloud. The AWS Migration Hub provides a location to monitor and manage migrations from on premises to the cloud. Once in the cloud, AWS Systems Manager helps an IT team configure on-premises servers and AWS instances.
Amazon also has partnerships with several technology vendors that ease hybrid cloud deployments. VMware Cloud on AWS brings software-defined data center technology from VMware to the AWS cloud. Red Hat Enterprise Linux for Amazon EC2 is the product of another partnership, extending Red Hat's operating system to the AWS cloud.
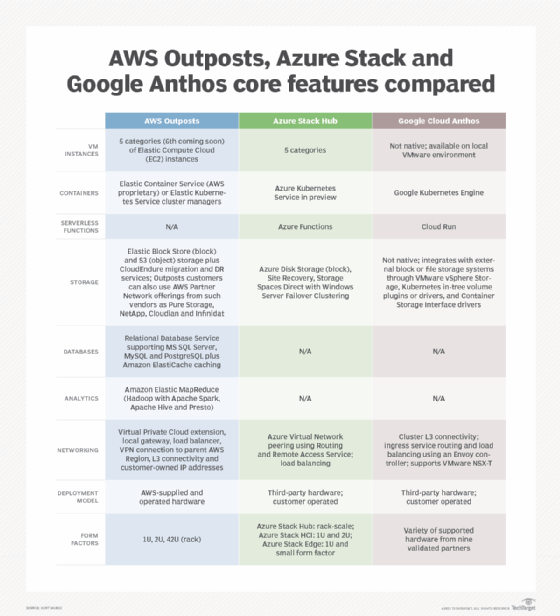
Once applications, databases, servers and data are migrated to the cloud or a hybrid environment, tools like AWS Outposts deliver AWS services and infrastructure across multiple environments.
Networking
An Amazon Virtual Private Cloud (Amazon VPC) gives an administrator control over a virtual network to use an isolated section of the AWS cloud. AWS automatically provisions new resources within a VPC for extra protection.
Admins can balance network traffic with the Elastic Load Balancing service, which includes the Application Load Balancer and Network Load Balancer. AWS also provides a domain name system called Amazon Route 53 that routes end users to applications.
An IT professional can establish a dedicated connection from an on-premises data center to the AWS cloud via AWS Direct Connect.
Developer tools
A developer can take advantage of AWS command-line tools and software development kits (SDKs) like AWS CloudShell to deploy and manage applications and services:
- AWS Command Line Interface, which is Amazon's proprietary code interface.
- AWS Tools for PowerShell, which developers use to manage cloud services from Mac, Windows and Linux environments.
- AWS Serverless Application Model, which developers use to simulate an AWS environment to test functions of AWS Lambda, which is a compute service that lets developers run code from more than 200 AWS services and SaaS applications.

AWS SDKs are available for a variety of platforms and programming languages, including Android, C++, Go, iOS, Java, JavaScript, .Net, Node.js, PHP, Python, Ruby and SAP ABAP.
Amazon API Gateway lets a development team create, manage and monitor custom application programming interfaces (APIs) that let applications access data or functionality from back-end services. API Gateway manages thousands of concurrent API calls at once.
AWS also provides Amazon Elastic Transcoder, a packaged media transcoding service, and AWS Step Functions, a service that visualizes workflows for microservices-based applications.
A development team can also create continuous integration and continuous delivery pipelines with the following services:
- AWS CodePipeline to model and automate the steps of the software release process.
- AWS CodeBuild to automate the writing and compiling of code.
- AWS CodeDeploy, which can be used with AWS Lambda, to automatically deploy code in EC2 instances.
- AWS CodeStar, a cloud-based service for managing various AWS projects.
- AWS Cloud9 to write, run and debug code in the cloud.
A developer can store code in Git repositories with AWS CodeCommit and evaluate the performance of microservices-based applications with AWS X-Ray.
AWS also offers the following machine learning (ML) services for developers:
- AWS CodeWhisperer, which provides code recommendations to developers based on prior code they've used.
- AWS CodeArtifact, a development paradigm for building ML models.
- Amazon SageMaker, a fully managed service that helps developers and data scientists build and deploy ML models.
Management and monitoring
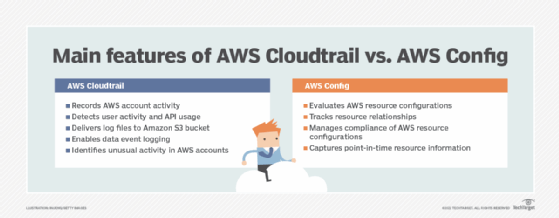
An admin can manage and track cloud resource configuration using AWS Config and AWS Config Rules. Those tools, along with AWS Trusted Advisor, can help an IT team avoid improperly configured and needlessly expensive cloud resource deployments.
AWS provides several automation tools in its portfolio. An admin can automate infrastructure provisioning via AWS CloudFormation templates, and also use AWS OpsWorks for Chef Automate to automate infrastructure and system configurations.
An AWS customer can monitor resource and application health with Amazon CloudWatch and the AWS Personal Health Dashboard. Customers can also use AWS CloudTrail to retain user activity and API calls for auditing, which has some key differences from AWS Config.
Security and governance
AWS provides a range of services for cloud security, including AWS Identity and Access Management, which lets admins define and manage user access to resources. An admin can also create a user directory with Amazon Cloud Directory or connect cloud resources to an existing Microsoft Active Directory with the AWS Directory Service. Additionally, the AWS Organizations service lets a business establish and manage policies for multiple AWS accounts.
Amazon Web Services has also introduced tools that automatically assess potential security risks. Amazon Inspector analyzes an AWS environment for vulnerabilities that might impact security and compliance. Amazon Macie uses ML technology to protect sensitive cloud data.
AWS also includes tools and services that provide software- and hardware-based encryption, protect against distributed denial-of-service (DDoS) attacks, acquire secure sockets layer and Transport Layer Security certificates, and filter potentially harmful traffic to web applications.
The AWS Management Console is a browser-based graphical user interface for AWS. It can be used to manage resources in cloud computing and cloud storage as well as security credentials. The AWS Console interfaces with all AWS resources.
Big data management and analytics
AWS includes the following big data analytics and application services:
- Amazon EMR, which offers an Apache Hadoop framework to process large amounts of data.
- Amazon Kinesis, which provides tools to process and analyze streaming data.
- AWS Glue, which is a service that handles extract, transform and load jobs.
- Amazon OpenSearch Service, which enables a team to perform application monitoring, log analysis and other tasks with the open source tool.
- Amazon Athena for S3, which lets analysts query data.
- Amazon QuickSight, which helps analysts visualize data.
Artificial intelligence
AWS offers a range of AI model development and delivery platforms, as well as packaged AI-based applications.
The Amazon AI suite of tools includes the following:
- Amazon Lex for voice and text chatbot technology.
- Amazon Polly for text-to-speech translation.
- Amazon Rekognition for image and facial analysis.
- Amazon Textract to extract important text and data from documents.
- Amazon Kendra to enhance website and application searches.
- Amazon Forecast for end-to-end business prediction models.
- Amazon CodeGuru Security to automate code reviews and detect costly, inefficient code.
- Amazon Lookout for Equipment for predictive maintenance.
AWS also provides technology for developers to build smart apps that rely on ML technology and complex algorithms.
With AWS Deep Learning Amazon Machine Images, developers can create and train custom AI models with clusters of graphics processing units or compute-optimized instances. AWS also includes deep learning development frameworks for Apache MXNet and TensorFlow.
On the consumer side, AWS technologies power the Alexa Voice Service virtual assistant, and a developer can use the Alexa Skills Kit to build voice-based apps for Echo devices.
Healthcare workers use Amazon HealthLake to store, transfer and query a patient's healthcare data as well as Amazon Comprehend Medical, which extracts information from medical text.
Mobile development
The AWS Mobile Hub offers a collection of tools and services for mobile app developers. One of those tools is the AWS Mobile SDK, which provides code samples and libraries.
A mobile app developer can also use Amazon Cognito to manage user access to mobile apps, as well as Amazon Pinpoint to send push notifications to application end users and analyze the effectiveness of those communications.
Messages and notifications
AWS messaging services provide core communication for users and applications. Amazon Simple Queue Service (SQS) is a managed message queue that sends, stores and receives messages between components of distributed applications to ensure the parts of an application work as intended.
Amazon Simple Notification Service (SNS) enables a business to send publish-subscribe messages to endpoints, such as end users or services. SNS includes a mobile messaging feature that enables push messaging to mobile devices. Amazon Simple Email Service provides a platform for IT professionals and marketers to send and receive emails.
Augmented reality (AR) and virtual reality (VR)
AWS offers AR and VR development tools through Babylon.js and AWS Sumerian. Babylon.js lets users create AR and VR applications without needing to know programming or create 3D graphics. The service also enables users to test and publish applications in-browser. Babylon.js can be used for 3D web applications, e-commerce, sales applications, marketing, online education, manufacturing, training simulations and gaming.
Amazon Sumerian lets developers create and run VR, AR, and 3D applications without requiring specialized programming or 3D graphics expertise. With Sumerian, developers can build highly immersive and interactive scenes that can run on hardware such as Oculus Go, HTC Vive, Google Daydream and Lenovo Mirage, as well as Android and iOS mobile devices. Sumerian provides building blocks for creating 3D experiences from a web browser, such as adding objects, designing environments and scripting interactions.
AWS also provides various immersive experience tools, such as Amazon AR View and Amazon AR App.
Game development
AWS can also be used for game development. Large game developing companies use AWS services for games, such as Ubisoft's For Honor. AWS can provide services for each part of a game's lifecycle.
For example, AWS provides developer back-end services, analytics and developer tools such as Amazon Lumberyard, which aid developers in making 3D games. Back-end services like Amazon GameLift help with building, deploying and scaling a developer's platform, as well as defending against DDoS attacks.
Analytics help developers know their customers and how they play a game. Developers can also store data and host game data on AWS servers.
Internet of things (IoT)
AWS has a variety of services that enable IoT deployments. The AWS IoT service provides a back-end platform to manage IoT devices and data ingestion to other AWS storage and database services.
The Amazon IoT Button provides hardware for limited IoT functionality and AWS IoT Greengrass brings AWS compute capabilities to IoT devices.
Other services
Amazon Web Services has a range of business productivity SaaS options:
- Amazon Chime, which enables online video meetings, calls and text-based chats across devices.
- Amazon WorkDocs, a file storage and sharing service.
- Amazon WorkMail, a business email service with calendaring features.
AWS has these desktop and streaming application services:
- Amazon WorkSpaces, a remote desktop-as-a-service platform.
- Amazon AppStream, a service that lets a developer stream a desktop application stored in the AWS cloud to an end user's web browser.
AWS also offers these blockchain services:
- Amazon Managed Blockchain, a service that helps create and manage blockchain networks.
- Amazon Quantum Ledger Database, a ledger database that records and stores a user's blockchain activity.
Also available are Amazon Braket, a service that aids developers in quantum computing research, and AWS RoboMaker, a service that lets developers create and deploy robotics applications.
For more on public cloud, read the following articles:
Key characteristics of cloud computing
The pros and cons of cloud computing explained
Public vs. private vs. hybrid cloud: Key differences defined
AWS benefits and drawbacks
With its array of service offerings, AWS is able to address many IT issues and needs. The major benefit of moving to a cloud environment is that it can save an organization money on physical data centers and related investments. AWS provides extensive service flexibility and scalability features. It also relieves customers from having to worry about security, reliability and compliance issues.
Despite its flexible pricing models, AWS can be expensive, depending on how much a particular service is used. Users must define their requirements carefully before launching an AWS product to assess whether cloud services are the most economical option.
The AWS environment is also large and complex, which can be challenging for new users. Loss of control is a common issue for cloud service customers, because the CSP handles administrative functions, unless otherwise arranged by the user. Security of AWS services is a prime focus for Amazon, yet it is still the user's responsibility to ensure their data and systems are secure. And despite its global network of data centers, AWS can also experience downtime.
AWS pricing models, competition and customers
AWS's pay-as-you-go model for its cloud services is either on a per-hour or per-second basis. There is also an option to reserve a set amount of compute capacity at a discounted price for customers who prepay or sign up for one- or three-year usage commitments. Customers can get volume-based discounts, meaning the more of a service they use, the less they pay per gigabyte.
The AWS Free Tier is another option. Customers can access up to 60 products and start building on the AWS platform at no cost. Free Tier is offered in three different options: always free, 12 months free and free trials.
Potential customers can use AWS's pricing calculator to estimate expenditures. And AWS-certified third-party experts provide on-demand help to customers picking a pricing plan.
As of the third quarter of 2023, AWS controlled 32% of the total cloud market, according to Synergy Research Group. In the IaaS market, AWS is the market share leader, ahead of Microsoft Azure, Google Cloud and IBM. Companies using AWS include the following:
- Airbnb.
- AstraZeneca.
- BMW Group.
- Capital One.
- Coca-Cola.
- Fox.
- Goldman Sachs.
- Heineken.
- Netflix.
- NFL.
- Philips.
- Pinterest.
- Salesforce.
- Toyota.
History
The AWS platform was launched in 2002 with a few services. In 2003, it was reenvisioned to make Amazon's compute infrastructure standardized, automated and web service focused. This change included selling access to a virtual-servers-as-a-service platform. In 2004, the first publicly available AWS service -- Amazon SQS -- was launched.
In 2006, AWS was relaunched to include three services -- Amazon S3, SQS, and EC2 -- officially making AWS a suite of online core services. In 2009, S3 and EC2 were launched in Europe, and the Elastic Block Store and Amazon CloudFront were released and adopted to AWS. In 2013, AWS started offering a certification process in AWS services, and 2018 saw the release of an autoscaling service.
In 2022 Amazon introduced more than 110 new and updated features and services at its re:Invent 2022 conference. Some of those new offerings included the following:
- AWS CodeCatalyst simplifies the process for development teams to quickly build and deliver scalable applications on AWS.
- AWS Application Composer is a low-code drag-and-drop application development tool for serverless apps.
- AWS Data Exchange for AWS Lake Formation assists data subscribers in finding and subscribing to third-party data sets that are managed directly through AWS Lake Formation.
- AWS Glue Data Quality automatically monitors and measures data quality and provides recommendations.
- AWS VPC Lattice is a networking service that connects, monitors and secures communications among user services to improve productivity; it also defines policies for network traffic management, access, and monitoring.
- AWS Security Lake automatically centralizes security data from AWS environments, SaaS providers, on-premises and cloud sources into a purpose-built data lake stored in a user's AWS account.
- AWS Supply Chain unifies supply chain data and provides insights, contextual collaboration and demand planning; it can connect to existing enterprise resource planning and supply chain management systems.
Today AWS offers more than 200 services and has data centers around the world that make it a highly available and scalable platform.
Acquisitions
AWS has acquired and invested in more than 120 organizations. Generally, it hasn't acquired larger well-established companies but smaller organizations and startups that bolster and improve the cloud vendor's existing offerings. Here are some of its recent acquisitions:
- GlowRoad. Bought in 2022 for its work-from-home software to help build and sell products worldwide.
- Veeqo. Another 2022 acquisition for its multichannel shipping software.
- MGM Studios. A 2022 purchase as part of Amazon's expansion into the entertainment industry.
- Zoox. Bought in 2020 for its autonomous vehicle technology.
Amazon has made a series of moves with generative AI. Find out more about what AWS is doing with GenAI.







