
beawolf - Fotolia
Navigate the AWS Lambda lifecycle to give functions a tuneup
Concurrency limits and cold starts affect the performance of Lambda functions. Gain a deeper understanding of how the service really works to cut down on unnecessary delays.

AWS Lambda functions are ideal to run simple tasks that take under five minutes, without requiring you to manage servers. However, they also don't maintain persistence, which means each time a function executes, there's no guarantee it will run on the same hardware or virtual instance.
This makes it difficult to do things like cache requests locally for performance enhancements, unless that cache is for the same individual request. So, how exactly do these functions operate?
Once you wrap your head around the AWS Lambda lifecycle, you can make better decisions about how to create and manage functions.
When you deploy Lambda functions, they follow a spin-up process -- which you aren't charged for -- before they actually execute the transaction-specific code. It's important to understand other features about functions, too -- including that they run inside a container to help isolate your code from other users' functions that run on the same hardware.
Shorten your cold-start times. Here's a closer look at the AWS Lambda lifecycle:
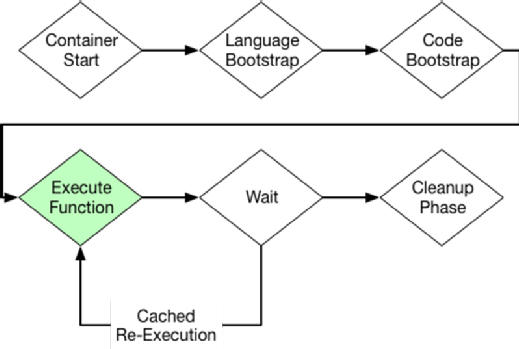
, Lambda functions run bootstrapping code for the language, and then spin up application code, all within its cold-start phase. Lambda "knows" there will be some bootstrapping time, so it can reuse the function containers after the execution is completed. Containers freeze after they finish execution, and then thaw again for reuse at a later time.
When the application is ready to accept connections, your timer starts. This means any code outside of your handler function -- the entry point that's called in response to an event -- can run for free, but it also means that code must run for every cold start before your function can accept requests.
The easiest way to see how this element of the AWS Lambda lifecycle works is to write a simple Lambda function with a concurrency limit of one, so that only one instance can run at a time. Then, issue constant commands to run on that function, with a counter variable outside of the handler function:
var counter = 0;
exports.handler = async (event) => {
counter++;
console.log('Counter', counter);
return `Counter says ${counter}`;
};
After you enter this code into the Lambda console and set the concurrency limit to one, run a few test events. You'll notice that each time you execute the Lambda function, the counter increases, even though brand requests were issued on each execution. This is because the Lambda function freezes the container for a period of time after execution is completed, and then reuses that same container for the next execution. The counter variable stores outside of the handler function, so it's part of the saved state that loads back into the next execution. Wait an hour or save a version of your function, then try again; you'll notice the counter returns back to one on the next execution, after the Lambda function terminates because that frozen Lambda container has been garbage collected and a one is built instead.
So, while it's important for your functions to have a short cold-start time, you should also take advantage of caching, as well as perform any common tasks outside of your main handler, as those operations only happen once per concurrent execution.
Lower concurrency limits can improve performance
Contrary to common wisdom, if you reduce concurrency, it might actually boost performance for certain functions. For example, if your function takes 30 seconds to start but only one second to actually execute, the execution would take 31 seconds, but the second would only take one second. If a request comes 15 seconds later, the third execution would still take 31 seconds.
But, if you set the concurrency level to one, the second execution would only take 17 seconds because it would wait for the to finish, and then reuse the same container. This timing graph depicts the different function times:
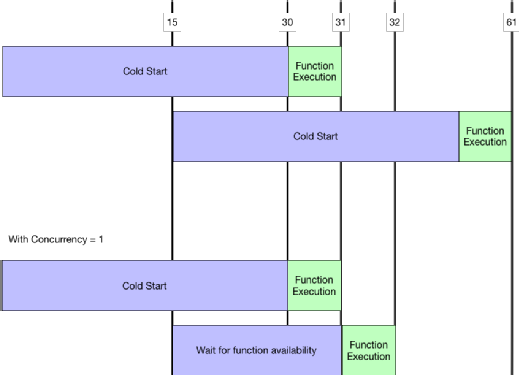
As you can see, it makes sense to for container reuse rather than concurrent executions in certain scenarios. However, this type of request doesn't scale very well. So, you should only lower concurrency for tasks that take a long time to bootstrap but don't often have multiple requests at the same time.
Lambda concurrency with DynamoDB throughput
It's fairly common to use Lambda functions along with DynamoDB or another database that has limited throughput. Lambda functions by execution time, which means you are charged while waiting for DynamoDB to respond. This means if your DynamoDB table capacity is set to allow five concurrent writes, but you have 20 concurrent Lambda functions trying to write to that table, 15 of those functions might get stuck waiting for write capacity. Instead, limit your Lambda concurrency to the same value your DynamoDB table can handle to avoid waiting for DynamoDB to be ready for requests.
Additionally, it's important to set up alarms, so if you have a lot of throttled Lambda requests, you can scale up your DynamoDB and concurrency limits. Enable AWS X-Ray to help identify bottlenecks within Lambda and determine how many concurrent requests your Lambda function can handle before you need to increase database throughput capacity.
Prewarm your functions
Lambda automatically scales, and it doesn't require you to pay for time without requests. However, if your function takes a long time to load or execute the request, it can help to prewarm the function.
Let's consider a function that associates key phrases to a category -- such as one that could map the phrase "this is spam" to the "spam" category. If there's a large amount of key phrases, it could take a while to load them all into , so this is likely the longest part of the request.
Let's assume our function looks like this:
# Pre-Cache all the markers
marker_cache = load_marker_cache()
def lambda_handler(event, context):
# Return immediately if we're just warming
if event.warm:
return ''
return categorize(event.text)
We would then create a CloudWatch Events rule to run every hour, with this predefined input:
{ warm: true }
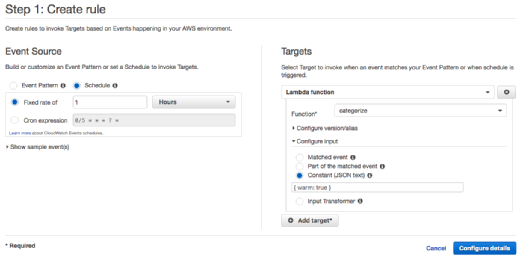
When the function detects the warm event, it simply returns an empty string instead of running the complex categorization function. This effectively keeps the function warm and ready for a request, without running anything unnecessarily. The function should return almost instantly, which means you won't be charged for more than a second of Lambda usage every hour, with the exception of the time to build the cache.
Make sure to set the Reserve concurrency to one, so that only one version of this function is needed and remains cached.
In the end, despite how they might seem, Lambda functions are not pure magic. Developers need to understand the AWS Lambda lifecycle to properly build functions that can scale with demand. And, sometimes it's better to make users wait a little bit longer rather than take down a database that's trying to query thousands of requests at a time.






