What is cloud management? Definition, benefits and guide
Cloud management refers to the exercise of control over public, private or hybrid cloud infrastructure resources and services. This involves both manual and automated oversight of the entire cloud lifecycle, from provisioning cloud resources and services, through workload deployment and monitoring, to resource and performance optimizations, and finally to workload and resource retirement or reallocation. A well-designed cloud management strategy can help IT pros control those dynamic and scalable cloud computing environments.
Cloud management can also help organizations achieve three goals:
- Self-service refers to the flexibility achieved when cloud users access cloud resources, create new ones, monitor usage and cost, and adjust resource allocations -- without the intervention of IT professionals or cloud service providers.
- Workflow automation lets operations teams manage cloud instances without human intervention. This is a key element in any automation infrastructure used for workload deployment and monitoring.
- Cloud analysis helps track cloud workloads and user experiences. This is essential for the management and optimization of cloud costs and performance.
Without a competent IT staff in place, it's difficult for any cloud management strategy to succeed. These individuals must be well-versed in cloud technologies. Further, they must possess knowledge of the proper tools and best practices to meet the cloud management goals of the business.
Why is cloud management important?
Clouds are an increasingly critical computing infrastructure component for many businesses. It costs money to use a cloud, and reliance on such a remote third-party infrastructure places enormous emphasis on the need for management. Cloud users must know that workload deployments are available and functioning properly at all times across a wide range of circumstances. When trouble strikes a workload or any part of the cloud's availability, customers must recognize and address the disruptions. Cloud users must also have a complete understanding of cloud costs and cost variabilities in order to set appropriate cloud budgets -- and release costly resources that are no longer needed. All of this demands careful and conscientious management.
There are many ways to approach cloud management, and they are ideally implemented in concert. Cost monitoring tools can help IT teams navigate complex vendor pricing models. Applications run more efficiently when they use performance optimization tools and with architectures designed with proven methodologies. Many of these tools and strategies dovetail with environmentally sustainable architectural strategies to lower energy consumption. Cloud management decisions must ultimately hinge on individual corporate priorities and objectives, as there is no single approach.
Companies are more likely to improve cloud computing performance, reliability, cost containment and environmental sustainability when they adhere to tried-and-true cloud optimization practices.
How does cloud management work?
Effective cloud management relies on two vital elements: tools and practices.
In terms of tools, cloud management operates as one or more software tools (a management platform) designed to discover, provision, track utilization, measure performance and produce reports on the cloud resources and services utilized by a client organization.
Cloud management tools are often supplied by the cloud provider itself in the form of a service. Such native tools are convenient and well-supported by the provider, and they can offer significant insights into the provider's infrastructure. The provider handles all the tool installation and maintenance, and users are billed on a monthly basis -- just as with most other cloud costs.
The tools can be purchased from a third-party provider and then deployed in a local data center or within the cloud itself inside a cloud virtual machine (VM). In other cases, organizations might choose third-party tools available as an independent SaaS offering deployed and supported by SaaS providers. Third-party cloud management tools are often best suited for managing multi-cloud environments -- sometimes termed unified cloud management -- where the provider's native management tools might not support the resources and services of other cloud providers.
In terms of practices, it's important for cloud users to establish clear guidelines or consistent workflows in the following areas:
- Defining approvals for utilization, such as budget references.
- Clarifying how resources and services are composed and utilized for workloads.
- Imposing requirements for security and compliance, such as data access and data protection.
- Selecting salient metrics and KPIs for performance and other factors.
- Creating meaningful reports that enable technology and business leaders to glean insights into cloud use for the organization's unique use case.
Cloud practices can be translated into cloud management tool setups and configurations so that the tools operate in accordance with business needs and goals outlined by practices. For example, a cloud management tool can be configured to display a web-based custom management dashboard that provides real-time views of cloud-based applications, performance data, traffic levels or transactional activity, as well as showing alerts other important events.
What are the benefits of cloud management?
When implemented correctly and configured appropriately, cloud management can bring an array of tangible benefits to the business. The following are some typical cloud management benefits:
- Improved cost control. Cloud resources and services cost money and can be deployed by almost any user with access to a cloud account. Management tracks and reports the resources and services being used, enabling businesses to gauge usage against cost. This can help prevent cloud waste and sprawl by identifying underutilized or obsolete cloud usage, which can be released for cost savings.
- Consistent control. Cloud management basically reflects the organization's best practices and priorities, which can be tracked and enforced in a consistent way. With this, the entire organization is held to the same consistent standards in cloud usage.
- Improved compliance and data protection. Cloud management almost universally implements strong authorization and authentication in the deployment of its resources and services. This can provide a meaningful platform for improved security, auditable data access, automated data backups and copies, and well-planned support for compliance requirements within the typical cloud shared responsibility model.
- Better business insights. Cloud management reporting can help identify cloud usage by team, group, project or business division. This can help business leaders identify highest cloud usage against revenue or budget for better insights regarding how the cloud is actually being used -- and what that cloud use is bringing to the business.
What are the goals and characteristics of cloud management?
Arguably the biggest challenge to cloud management is cloud sprawl, which is exactly what it sounds like: IT staff loses track of cloud resources, which then multiply unchecked throughout the organization while the organization continues paying the costs of those resources and services each billing cycle. Cloud sprawl can increase costs and create security and management problems, so IT teams need governance policies and role-based access controls in place.
Start with a cloud migration strategy that incorporates proper documentation and ensures only necessary data and workloads are moved off premises. Address multi-cloud management, self-service portals for users and other forms of provisioning and orchestration.
Cloud management platforms provide a common view across all cloud resources to help monitor both internal and external cloud services. Management platform tools can help guide all individuals that touch an application's lifecycle. Regular audits can keep resources in check. Finally, consider specialized third-party tools to help fine-tune enterprise usage, performance, cost and business benefits.
Be sure to set metrics to help identify trends and provide guidance on what you want to measure and track over time. There are plenty of potential data points, but every enterprise should choose the ones that matter most to their business. Consider the following:
- Data about the utilization of a compute instance's volume and performance -- processor, memory, disk, etc. -- provides insight about the application's overall health and availability.
- Storage consumption refers to storage tied to the compute instances or persistent storage allocated to containers.
- Load-balancing services distribute incoming network traffic across multiple workload instances for better performance and/or resilience.
- Database instances help pool and analyze data.
- Cache instances use memory to hold frequently accessed data and thus enhance workload performance by avoiding the need to use slower media, such as disk storage.
- Functions, also called serverless computing services, are used to provision workloads and avoid the need to supply and pay for compute instances. The cloud provider operates the service that loads, executes and unloads the function when it meets trigger parameters.
- APIs are carefully tracked and performance time per-call can be measured, with pricing often set on a per-call basis.
What are the challenges of cloud management?
Cloud management can be a complex undertaking, with challenges in important areas including security, cost management, governance and compliance, automation, provisioning and monitoring.
Security management
The major public cloud vendors continue to invest in their services and improve cloud security, such as their ability to fend off distributed denial-of-service attacks. Some experts say that today's cloud attacks are far less devastating than on-premises ones because cloud attacks are generally limited to a single misconfigured service, whereas a local attack might devastate an entire infrastructure.
Nevertheless, IT staff must remain vigilant to guard against security threats. Google, AWS and Microsoft, among others, do not take full responsibility to keep cloud data safe. Cloud users must understand their shared responsibility in the cloud to protect their data. Here is the simplest way to express shared responsibility of cloud data:
- Providers are responsible for the security of the cloud, such as proper system and network configurations.
- Users are responsible for security in the cloud, such as utilizing proper authentication and authorization and provisioning.
For example, if the provider can be expected to offer identity and access management security for its cloud resources and services, it's up to the cloud user to actually select and use those services in a cloud deployment. A lapse on either side of the shared responsibility model can leave workloads and data vulnerable to attack.
Cloud security best practices include configuration management, automated security updates on SaaS and improved logging and access management. Cloud configurations today are more standard, and standard configurations are easier to secure.

Security dashboards and trend analysis tools let enterprises look into their environment to help it stay secure. Cloud versions are far more flexible than the tools that live on premises. For instance, an enterprise can activate a service provider's online dashboard and quickly receive visibility into an online attack.
Cloud security challenges. Cloud security breaches and incidents still occur, even as security technologies improve and service providers gird their networks. Malicious actors can attack network hosts and web apps as fast as they can be fortified. Cloud administrators should test their environments and review the latest security audits and reports. Take care when adopting new technologies, such as AI and machine learning, which use many diverse and distributed data sources and therefore broaden the range for potential attacks.
Cost management
Cloud computing costs can spiral if they are not managed from the start. Numerous short-term and long-term cost optimization strategies for cloud configurations can help keep budgets in line.
There are two major cost management issues to consider: sprawl and rightsizing.
Sprawl is basically idle waste. Cloud resources and services are provisioned for a workload and data; over time, the workload and data fall into disuse, are replaced by other business applications and data or simply reach the end of their anticipated business lifecycle. Ideally, such resources and services should be relinquished (freed) to stop corresponding monthly cloud fees. When business users fail to relinquish unneeded resources and services, however, they are easily forgotten and can cost the business significant costs month over month. Cloud management tools can report on consumed services and traffic levels to help businesses identify and release unneeded cloud resources.
The second issue is rightsizing. Providers offer almost limitless resources in a wide range of sizes and capacities -- each with different price points. Choosing the right set of resources and services for an application will help the business architect a deployment infrastructure that offers the optimum mix of performance, reliability and cost.
To mitigate these concerns, start with choosing the right provider. There are different ways to run an application: hosted on VMs on a service, containerized or hosted in a serverless computing environment. Each has varying cost and management complexity. The trick is to find the right balance between cost and enterprise needs. Apply the following considerations:
- Determine how much redundancy your application needs. One way to achieve cloud redundancy is to pick a hosting option that distributes workloads across multiple data centers within a region. This is a low-cost strategy but has the least amount of redundancy. Another way is for users to mirror workloads across more than one region, which offers more redundancy but at a higher cost.
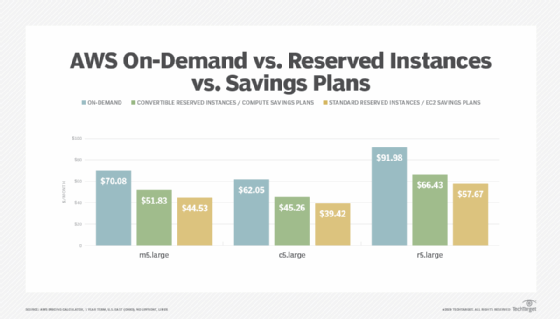
- Determine the appropriate size and scale for your installation. Tools can help identify a more efficient -- meaning less expensive -- VM instance for the workload you want to run. Reserved instances cost less than on-demand VMs, though they must be booked in advance. Preemptible instances are cheapest but risk interruption by the cloud service provider, so they aren't a fit for consistent workloads that require uptime. Autoscaling, typically part of a cloud vendor's overall framework, can increase or decrease resources as demand shifts.
- Minimize data movement. Cloud providers charge for data egress. If you move data frequently, choose the appropriate cloud services setup for that. Also, recognize that moving data can increase security risks.
- Consider third-party tools. Third-party cost-management tools might offer better capabilities for management, monitoring and security than a cloud platform's native services. They also tend to work in multi-cloud environments.
- Look to advanced technologies for assistance. Cloud management can be tricky, even if you do everything right. Some users and experts believe artificial intelligence and machine learning can efficiently and significantly reduce cloud costs. Vendors already offer tools that incorporate capabilities to scan cloud workloads, quickly detect anomalies and alert administrators about an issue that might affect the cloud bill.
Cost management challenges. Detailed information about cloud costs might not be easily accessible. A customer could search across regions, accounts and numerous attached cloud services to calculate the total cost for just one individual service, such as backup snapshots. Emerging cloud practices, such as FinOps, can help business teams identify and manage diverse and seemingly disassociated costs.
The COVID-19 pandemic and related economic factors spurred enterprises to move more workloads to the cloud, which underscores the need for cost optimization practices.
AI tools and machine learning supplement the actions of humans, but don't replace them. Software can identify additional information that staff might miss, but people must collaborate when analyzing cloud cost strategies and make judgment calls based on resources and experience. In-house staff should know how cloud usage affects the bottom line, both in IT and business lines.
Governance and compliance
Data governance and compliance are hardly new concerns. Longstanding regulations, such as the Health Insurance Portability and Accountability Act (HIPAA), affect how data is stored and used. However, regulations have become more numerous and localized, presenting new governance and compliance problems for businesses -- and cloud providers -- operating in different jurisdictions around the world.
In recent years, cloud vendors have grappled with a spate of new regulations that govern how they can use personal data. Specifically, the EU's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) took effect. Cloud providers offered different responses to these regulations, but in general their services comply with regulations that involve data transparency.
A bigger challenge is how cloud providers help customers ensure compliance while they use these platforms. Amazon, Google, Microsoft and others offer resource portals to guide customers through the compliance process. Many multi-jurisdictional businesses employ regulatory compliance officers that must possess expertise in many regulations and their impacts across different jurisdictions. That knowledge is then translated into process, policy and cloud deployments that best meet prevailing regulatory requirements.
Cloud governance and compliance challenges. IT pros have their hands full keeping up in the current regulatory environment. Around the world, data protection teams are overwhelmed by the sheer number of discovery and other legal requests that increase their workload, particularly regarding the GDPR. There is also a need to fight the false notion that just because one is compliant, one is secure; adherence to compliance standards does nothing to stop phishing attacks or other cloud breaches. Hone your organization's alignment with regulations and rules by using a cloud governance framework.
Cloud automation
Cloud automation reduces the repetitive, manual work needed to deploy and manage cloud workloads. Automation typically works in tandem with orchestration, which is the mechanic by which automation is implemented. Ideally, automation and orchestration can reduce a myriad of complex and time-consuming steps into a single script or click. The main idea is to boost operational efficiencies, accelerate application deployment and reduce any human error -- mainly in security and configuration -- that can potentially jeopardize application security, stability and reliability. To achieve this, IT pros need orchestration or automation tools.
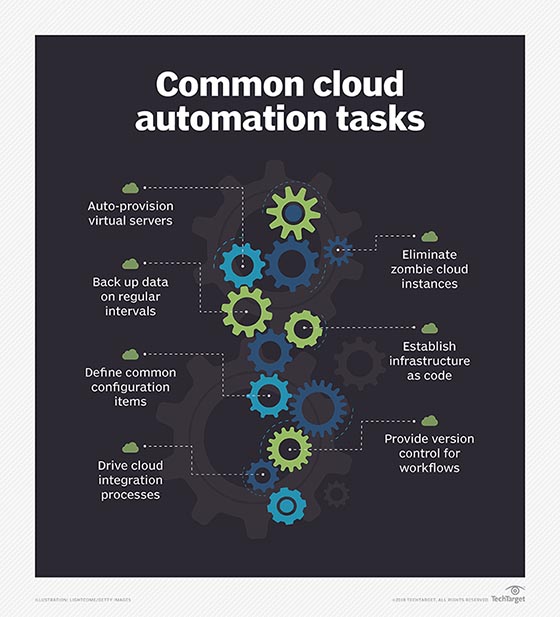
Software targets different areas of cloud automation, from on-premises tools for private clouds to hosted services from the big cloud service providers, such as Microsoft Azure Automation, Google Kubernetes Engine and the automation feature in AWS Systems Manager.
Cloud automation challenges. Automation typically saves time and money, but a big challenge for enterprises is that users might feel automation will put them out of a job. In most cases, automation supplements a job and frees up the cloud pro to do other work. In more realistic terms, automation can demand significant upfront work and expertise to set up and test, as well as regular reviews to reevaluate and update established automated processes as business and workload needs change.
Cloud provisioning
Cloud provisioning refers to how a customer procures and orchestrates the use of a cloud provider's resources and services, from compute and VM instance storage volumes to additional capabilities, such as network and database services, data analytics and machine learning.
Proper resource allocation starts with rightsizing instances and VMs for appropriate scalability, which ideally occurs during the development phase. Optimized cloud capacity parameters not only ensure workloads run efficiently but also can prevent a lot of wasted money. Identify what an application requires to run properly and cut anything unnecessary. Cloud providers offer tools and templates to further optimize resource deployments.
There are three types of cloud provisioning models, with differences in the resources offered and how they are delivered and paid for:
- Advanced provisioning. The customer signs a formal contract of service with the cloud provider, which delivers agreed-upon resources and services. The customer is charged a flat fee or is billed on a monthly basis.
- Dynamic provisioning. Cloud resources are deployed to match a customer's fluctuating demands, typically scaled up to handle spikes in usage and scaled down when demands decrease. The customer is billed on a pay-per-use basis.
- Self-service provisioning. The customer buys resources from the cloud provider through a web interface or cloud brokerage portal. Resources are quickly made available for use, sometimes within hours or minutes.
A self-service brokerage will not completely eliminate administrative tasks, but it will shift some of the workload away from the IT service desk. IT ops teams still must maintain the portal and oversee the cloud environment.
Cloud provisioning challenges. The classic challenge here is to optimize the allocation of resources and services, balanced against various factors, such as performance, cost and security -- and the priorities for those might change. Many cloud services benefit from, or even depend upon, other services; users must understand these dependencies to not be caught off guard by unexpected usage and costs. Other challenges with provisioning involve the need to anticipate and avoid problems with security and policy enforcement. Cloud provisioning practices and problems are often aligned closely with cloud automation efforts.
Cloud monitoring
Cloud monitoring measures the conditions of a workload and the various quantifiable metrics and KPIs that relate to overall cloud operations. Results are monitored in specific, granular data, but that data often lacks context.
Cloud observability is a process similar to cloud monitoring in that it helps assess cloud health. Observability is less about metrics than what can be gleaned from a workload based on its externally visible properties. There are two aspects of cloud observability: methodology and operating state. Methodology focuses on specifics, such as metrics, tracing and log analysis. Operating state relies on tracking and addresses state identification and event relationships, the latter of which is a part of DevOps.
As an example, monitoring might reveal that the traffic level or response time of a cloud workload falls within acceptable parameters, but observability can help to define that workload's health and user experience.
Cloud monitoring challenges. One of the biggest challenges for IT teams is to keep up with modern and distributed application designs. As applications evolve, IT must adjust their monitoring strategies. Effective cloud monitoring is a complex task. The tools that an organization currently uses might no longer be the ones they need, as different types of applications will need to be monitored in different ways.
For example, monitoring a traditional monolithic application running within a single VM with a single associated storage volume can be very different than monitoring a similar microservices application deployed through myriad different containers, each with separate storage, and communicating through complex network connections. The amount of monitoring data produced -- and the resulting assessments of the workload's health and performance -- can place radically different demands on monitoring tools and practices.
How to improve cloud performance
The goal of cloud management is to achieve peak application performance within a given cloud environment. While there is no single architecture that can guarantee peak performance for every application, there are ways to help boost cloud performance across the board:
- Choose and use the right metrics. A key to improving performance is understanding the current performance criteria of the cloud and application. Understand the metrics and KPIs that are important to the application, such as transactions per second, and deploy the proper instrumentation needed to track and report that data. This is both the justification for change, and the point of reference against which change is objectively measured.
- Match applications with architectures. Applications can have different needs: more compute capacity for one, more storage for another and so on. Although automation and orchestration favor quick provisioning of standardized cloud environments -- invoking predesigned sets of cloud resources and services -- one-size cloud environments are rarely optimal and can require some adjustment to optimize application performance in the cloud.
- Rightsizing instances. As mentioned, start by selecting the right resources to run a workload. Optimizations might demand larger or more numerous compute instances to meet the given demands of the workload.
- Autoscaling. Public cloud computing is dynamic by nature, and you want to be able to add and subtract instances on demand. These services provide ways to apply rules to track when a workload exceeds or recedes from a certain threshold and trigger resources to readjust. Make the effort to test scaling to be sure it works as expected, and consider changing scaling criteria to optimize workload performance.
- Caching. Accessing storage can slow application responsiveness. With cached data, an application can execute tasks much faster than if it had to access data that resides in regular storage.
- Microservices. In a microservices architecture, an application's major features and functions are built in modular services. An application that is broken into a series of programs that are individually deployed, operated and scaled will be more responsive than one that's monolithic. Adopting a microservices architecture can be a challenging pursuit in itself, and existing legacy monolithic applications might need to be redesigned from scratch.
- Event-driven architectures. Also called serverless computing, event-driven architectures can run on cloud services, such as AWS Lambda, Azure Functions and Google Cloud Functions. Here, developers place code for certain software behaviors and functions into the cloud platform. It only operates when it's triggered by an actual event. When the function is complete, it no longer consumes cloud resources.
Another way IT teams can manage application performance in the cloud is through load balancing, which distributes network traffic so that each instance operates at peak efficiency. In prior days, load balancers operated locally as a data center appliance. Today, it is typically an application that lives on a server and is offered as a network service.
How to create and implement a cloud management strategy
There is no single universal approach to cloud management. Needs, tools, budgets and policies can vary dramatically between organizations. However, some common points in creating any cloud management strategy can include the following:
- Understand management goals. Any plan should start with the end in mind, so be clear on the reasons that are driving a cloud management initiative in the first place. The "why" of cloud management will have a profound impact on how the practice develops.
- Select desirable metrics. In knowing the overall goals of a cloud management initiative, a business can consider the underlying metrics and KPIs that need to be measured. For example, a focus on performance will likely prompt related metrics, such as transactions-per-second, while a focus on cost mitigation might prompt comprehensive cost reporting.
- Evaluate changes to policy and process. Cloud management is not the same as managing a local data center. It will require changes to business policies and workflows. It's important to consider and codify those changes so they can be implemented into a cloud management tool -- especially when automation and orchestration is a key goal.
- Select the most appropriate tools. Every cloud management tool can cater to specific business goals and pose a different set of tradeoffs for the business. Take the time to select tools based on needs, as well as desired metrics and intended workflows, and then test and validate several potential candidates before making the commitment to a specific cloud management tool.
- Realign management tasks. IT teams must also test cloud application performance, monitor cloud computing metrics, make critical infrastructure decisions, address patch and security vulnerabilities, and update the business rules that drive cloud management. Organizations also must rethink their change management policies for the cloud, where consumption of resources can be more much more rapid and spread out versus an on-premises IT environment.
- Organize the right staff. The success of any cloud management strategy depends not just on the proper use of tools and automation but also on having a competent IT staff in place. IT staff, business leadership, legal/compliance officers and application stakeholders/owners must collaborate effectively in order to embrace a cloud culture and understand the business goals.
- Seek additional training. Cloud management training should extend beyond IT and into other departments, from the supply chain to accounting teams. Staff can benefit from cloud training, such as certifications available through the CompTIA Cloud Essentials and AWS Cloud Practitioner programs. If traditional certification programs cost too much, consider online programs including LinkedIn Learning, A Cloud Guru, Linux Academy and others. Some businesses might consider the value of adopting FinOps practices for cloud cost management, and there is ample training available for FinOps practitioners.
- Consider outside help. Companies that lack a skilled IT staff can seek help from third parties. Third-party apps support budget threshold alerts that can notify finance and line-of-business stakeholders so they can monitor their cloud spending. Cloud brokerages often have a service catalog and some financial management tools. The time to scrutinize cloud spending is early on when apps go into production.
- Start small. Cloud management can be a big job, but it's rarely an all-or-nothing proposition. Adopt cloud management in phases, starting with smaller or lower-priority workloads. This can provide valuable time for cloud management staff to gain expertise with the tools and process, optimize tool capabilities and reporting, make and review changes, and plan the management of larger and more critical workloads with a greater sense of confidence.
- Periodically evaluate success. Implementing cloud management is just the beginning. Organizations must periodically review cloud management results against the established goals and consider whether those original goals are actually being met by the cloud management tools and practices in place. Changes might be needed when goals are not met (maybe the tool doesn't monitor and report on required metrics) or when goals change (maybe the business adopts a multi-cloud strategy and new tools and practices are needed).
Cloud management platforms, tools and vendors
As cloud computing expands across the enterprise, a general cloud management platform can help deploy, manage and monitor all cloud resources. Enterprise IT must form a clear idea on what it wants to monitor before evaluating cloud management platforms to fit those needs -- whether it's individual tools that solve a single problem, such as network performance or traffic analysis, or a comprehensive suite that looks at everything. Some of these decisions will weigh tools from cloud providers, such as security tools from cloud platform vendors or from third-party providers.
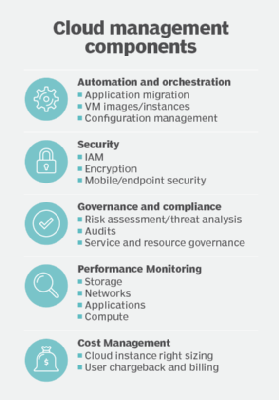
The most comprehensive cloud management products offer features that cover these five categories: automation and orchestration for applications and individual VMs; security, including identity management and data protection and encryption; policy governance and compliance, including audits and service-level agreements; performance monitoring; and cost management.
Many multi-cloud management vendors offer a range of tools, each with strengths and weaknesses. Some of the more prominent ones are VMware, CloudBolt Software, Snow Software (which acquired Embotics), Morpheus Data, Scalr and Flexera. Also in this mix are traditional IT service management vendors, such as IBM's Cloud Orchestrator, BMC Software, CA Technologies, Micro Focus and ServiceNow, which typically serve big companies with IT service management governance processes. Some tools, like CloudZero, focus on cloud cost management. Other tools, like Morpheus, specialize on self-service hybrid cloud management and automation. Still other tools, such as TotalCloud, emphasize the role of workflows and automation in cloud management, while CoreStack focuses on multi-cloud governance.
IT admins that use a single public cloud might want to stick with tools offered by that service provider because such tools are designed to enhance those native management platforms. For cloud monitoring, Google Cloud Operations (formerly Stackdriver) monitors Google Cloud as well as applications and VMs that run on AWS Elastic Compute Cloud. Microsoft Azure Monitor collects and analyzes data and resources from the Azure cloud. AWS users have Amazon CloudWatch. Other options include Oracle Cloud Infrastructure's Application Performance Monitoring service and Cisco CloudCenter, as well as tools such as Datadog for cloud analytics and monitoring, and New Relic to track web apps. There are also many open source cloud monitoring options for enterprises comfortable working with open source tools.
Ultimately, cloud management can be a complex and multifaceted endeavor, and businesses can use a combination of tools to support multiple business goals -- especially if the business employs multiple public clouds or a hybrid (public/private) cloud environment.
Private cloud management tools
For private cloud management, enterprises typically use in-house tools. Applications that run in a private cloud don't get the advantage of unlimited elasticity gained from public cloud services built on an enormous scale of infrastructure. The IT team must be certain that it has adequate, available resources to run the app and must carefully manage environments to ensure that no one app consumes too many corporate computing resources.
Some in-house tools can include platform-specific management software, such as Turbonomic Operations Manager (now owned by IBM) or Snow Commander. There are also private cloud management tools with sophisticated software frameworks that manage complex hybrid cloud deployments, such as AppDynamics, Microsoft System Center Virtual Machine Manager for Hyper-V, VMware vCloud Suite, HPE Private Cloud as a Service and Citrix Cloud. Private cloud frameworks frequently provide varied tools and services for management, such as OpenStack with its Horizon web dashboard and Heat orchestration tool.




