
cloud computing
What is cloud computing?
Cloud computing is a general term for the delivery of hosted computing services and IT resources over the internet with pay-as-you-go pricing. Users can obtain technology services such as processing power, storage and databases from a cloud provider, eliminating the need for purchasing, operating and maintaining on-premises physical data centers and servers.
A cloud can be private, public or a hybrid. A public cloud sells services to anyone on the internet. A private cloud is a proprietary network or a data center that supplies hosted services to a limited number of people, with certain access and permissions settings. A hybrid cloud offers a mixed computing environment where data and resources can be shared between both public and private clouds. Regardless of the type, the goal of cloud computing is to provide easy, scalable access to computing resources and IT services.
Cloud infrastructure involves the hardware and software components required for the proper deployment of a cloud computing model. Cloud computing can also be thought of as utility computing or on-demand computing.
The name cloud computing was inspired by the cloud symbol that's often used to represent the internet in flowcharts and diagrams.
How does cloud computing work?
Cloud computing lets client devices access rented computing resources, such as data, analytics and cloud applications over the internet. It relies on a network of remote data centers, servers and storage systems that are owned and operated by cloud service providers. The providers are responsible for ensuring the storage capacity, security and computing power needed to maintain the data users send to the cloud.
Typically, the following steps are involved in cloud computing:
- An internet network connection links the front end -- the accessing client device, browser, network and cloud software applications -- with the back end, which consists of databases, servers, operating systems and computers.
- The back end functions as a repository, storing data accessed by the front end.
- A central server manages communications between the front and back ends. It relies on protocols to facilitate the exchange of data. The central server uses both software and middleware to manage connectivity between different client devices and cloud servers.
- Typically, there's a dedicated server for each application or workload.
Cloud computing relies heavily on virtualization and automation technologies. Virtualization lets IT organizations create virtual instances of servers, storage and other resources that let multiple VMs or cloud environments run on a single physical server using software known as a hypervisor. This simplifies the abstraction and provisioning of cloud resources into logical entities, letting users easily request and use these resources. Automation and accompanying orchestration capabilities provide users with a high degree of self-service to provision resources, connect services and deploy workloads without direct intervention from the cloud provider's IT staff.
What are the different types of cloud computing services?
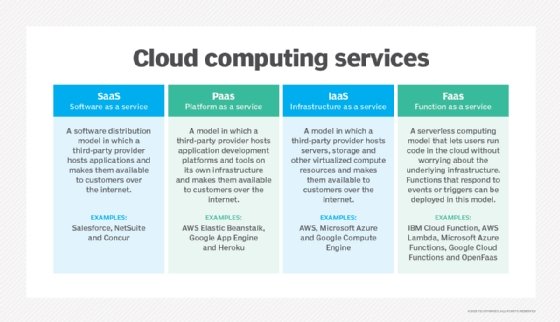
Cloud services can be classified into three general service delivery categories:
- Infrastructure as a service (IaaS). IaaS providers, such as Amazon Web Services (AWS), supply a virtual server instance and storage, as well as application programming interfaces (APIs) that let users migrate workloads to a virtual machine (VM). Users have an allocated storage capacity and can start, stop, access and configure the VM and storage as desired. IaaS providers offer small, medium, large, extra-large and memory- or compute-optimized instances, in addition to enabling customization of instances for various workload needs. The IaaS cloud model is closest to a remote data center for business users.
- Platform as a service (PaaS). In the PaaS model, cloud providers host development tools on their infrastructures. Users access these tools over the internet using APIs, web portals or gateway software. PaaS is used for general software development and many PaaS providers host the software after it's developed. Examples of PaaS products include Salesforce Lightning, AWS Elastic Beanstalk and Google App Engine.
- Software as a service (SaaS). SaaS is a distribution model that delivers software applications over the internet; these applications are often called web services. Users can access SaaS applications and services from any location using a computer or mobile device that has internet access. In the SaaS model, users gain access to application software and databases. An example of a SaaS application is Microsoft 365 for productivity and email services.
- Function as a service (FaaS). FaaS, also known as serverless computing, lets users run code in the cloud without having to worry about the underlying infrastructure. Users can create and deploy functions that respond to events or triggers. FaaS abstracts server and infrastructure management, letting developers concentrate solely on code creation.
Cloud computing deployment models
There are several cloud computing deployment methods, including the following:
Private cloud
A business's data center delivers private cloud services to internal users. With a private cloud, an organization builds and maintains its own underlying cloud infrastructure. This model offers the versatility and convenience of the cloud, while preserving the management, control and security common to local data centers. Internal users might be billed for services through IT chargeback. Examples of private cloud technologies and vendors include VMware and OpenStack.
Public cloud
In the public cloud model, a third-party cloud service provider (CSP) delivers the cloud service over the internet. Public cloud services are sold on demand, typically by the minute or hour, though long-term commitments are available for many services. Customers only pay for the central processing unit cycles, storage or bandwidth they consume. Examples of public CSPs include AWS, Google Cloud Platform (GCP), IBM, Microsoft Azure, Oracle and Tencent Cloud.
Hybrid cloud
A hybrid cloud is a combination of public cloud services and an on-premises private cloud, with orchestration and automation between the two. Companies can run mission-critical workloads or sensitive applications on the private cloud and use the public cloud to handle workload bursts or spikes in demand. The goal of a hybrid cloud is to create a unified, automated, scalable environment that takes advantage of all that a public cloud infrastructure can provide, while still maintaining control over mission-critical data.
Multi-cloud
Organizations are increasingly embracing a multi-cloud model, or the use of multiple IaaS providers. This lets applications migrate between different cloud providers or operate concurrently across two or more cloud providers.
Organizations adopt multi-cloud for various reasons, including to help them minimize the risk of a cloud service outage or take advantage of more competitive pricing from a particular provider. It also helps organizations avoid vendor lock-in, letting them switch from one provider to another if needed.
However, multi-cloud deployment and application development can be a challenge because of the differences between cloud providers' services and APIs. Multi-cloud deployments should become easier as cloud providers work toward standardization and convergence of their services and APIs. Industry initiatives such as Open Cloud Computing Interface aim to promote interoperability and simplify multi-cloud deployments.
Community cloud
A community cloud, which several organizations share, supports a particular community that has the same concerns, mission, policy, security requirements and compliance considerations. A community cloud is either managed by these organizations or a third-party vendor and can be on or off premises.
Characteristics of cloud computing
Cloud computing has been around for several decades and today's cloud computing infrastructure demonstrates an array of characteristics that have brought meaningful benefits to businesses of all sizes.
Characteristics of cloud computing include the following:
- Self-service provisioning. End users can spin up compute resources for almost any type of workload on demand. An end user can provision computing capabilities, such as server time and network storage, eliminating the traditional need for IT administrators to provision and manage compute resources.
- Elasticity. Companies can freely scale up as computing needs increase and scale down as demands decrease. This eliminates the need for massive investments in local infrastructure, which might not remain active.
- Pay per use. Compute resources are measured at a granular level, letting users pay only for the resources and workloads they use.
- Workload resilience. CSPs often deploy redundant resources to ensure resilient storage and to keep users' important workloads running -- often across multiple global regions.
- Migration flexibility. Organizations can move certain workloads to or from the cloud or to different cloud platforms automatically.
- Broad network access. A user can access cloud data or upload data to the cloud from anywhere with an internet connection using any device.
- Multi-tenancy and resource pooling. Multi-tenancy lets several customers share the same physical infrastructures or the same applications, yet still retain privacy and security over their own data. With resource pooling, cloud providers service numerous customers from the same physical resources. The resource pools of the cloud providers should be large and flexible enough so they can service the requirements of multiple customers.
- Security. Security is integral in cloud computing and most providers prioritize the application and maintenance of security measures to ensure confidentiality, integrity and availability of data being hosted on their platforms. Along with strong security features, providers also offer various compliance certifications to ensure that their services adhere to industry standards and regulations.
What are the benefits of cloud computing?
Cloud computing provides a variety of benefits for modern business, including the following:
- Cost management. Using cloud infrastructure can reduce capital costs, as organizations don't have to spend massive amounts of money buying and maintaining equipment, investing in hardware, facilities or utilities, or building large data centers to accommodate their growing businesses. In addition, companies don't need large IT teams to handle cloud data center operations because they can rely on the expertise of their cloud providers' teams. Cloud computing also cuts costs related to downtime. Since downtime rarely happens in cloud computing, companies don't have to spend time and money to fix issues that might be related to downtime.
- Data and workload mobility. Storing information in the cloud means users can access it from anywhere with any device with just an internet connection. That means users don't have to carry around USB drives, an external hard drive or multiple CDs to access their data. They can access corporate data via smartphones and other mobile devices, letting remote employees stay current with co-workers and customers. End users can easily process, store, retrieve and recover resources in the cloud. In addition, cloud vendors provide all the upgrades and updates automatically, saving time and effort.
- Business continuity and disaster recovery (BCDR). All organizations worry about data loss. Storing data in the cloud guarantees that users can always access their data even if their devices, such as laptops or smartphones, are inoperable. With cloud-based services, organizations can quickly recover their data in the event of natural disasters or power outages. This benefits BCDR and helps ensure that workloads and data are available even if the business suffers damage or disruption.
- Speed and agility. Cloud computing facilitates rapid deployment of applications and services, letting developers swiftly provision resources and test new ideas. This eliminates the need for time-consuming hardware procurement processes, thereby accelerating time to market.
- Environmental sustainability. By maximizing resource utilization, cloud computing can help to promote environmental sustainability. Cloud providers can save energy costs and reduce their carbon footprint by consolidating workloads onto shared infrastructure. These providers often operate large-scale data centers designed for energy efficiency.
What are the disadvantages of cloud computing?
Despite the clear upsides to relying on cloud services, cloud computing has its own challenges for IT professionals:
- Cloud security. Security is often considered the greatest challenge organizations face with cloud computing. When relying on the cloud, organizations risk data breaches, hacking of APIs and interfaces, compromised credentials and authentication issues. Furthermore, there's a lack of transparency regarding how and where sensitive information entrusted to the cloud provider is handled. Security demands careful attention to cloud configurations and business policy and practice.
- Unpredictable costs. Pay-as-you-go subscription plans for cloud use, along with scaling resources to accommodate fluctuating workload demands, can make it difficult to define and predict final costs. Cloud costs are also frequently interdependent, with one cloud service often using one or more other cloud services -- all of which appear in the recurring monthly bill. This can create additional unplanned cloud costs.
- Lack of expertise. With cloud-supporting technologies rapidly advancing, organizations are struggling to keep up with the growing demand for tools and employees with the proper skills and knowledge needed to architect, deploy and manage workloads and data in a cloud.
- IT governance difficulties. The emphasis on do-it-yourself in cloud computing can make IT governance difficult, as there's no control over provisioning, deprovisioning and management of infrastructure operations. This can make it challenging for organizations to properly manage risks and security, IT compliance and data quality.
- Compliance with industry laws. When transferring data from on-premises local storage into cloud storage, it can be difficult to manage compliance with industry regulations through a third party. It's important to know where data and workloads are actually hosted to maintain regulatory compliance and proper business governance.
- Management of multiple clouds. Every cloud is different, so multi-cloud deployments can disjoint efforts to address more general cloud computing challenges.
- Cloud performance. Performance -- such as latency -- is largely beyond the control of the organization contracting cloud services with a provider. Network and provider outages can interfere with productivity and disrupt business processes if organizations aren't prepared with contingency plans.
- Cloud migration. The process of moving applications and other data to the cloud often causes complications. Migration projects frequently take longer than anticipated and go over budget. The issue of workload and data repatriation -- moving from the cloud back to a local data center -- is often overlooked until unforeseen costs or performance problems arise.
- Vendor lock-in. Often, switching between cloud providers can cause significant issues. This includes technical incompatibilities, legal and regulatory limitations and substantial costs incurred from sizable data migrations.
Cloud computing examples
Cloud computing has evolved and diversified into a wide array of offerings and capabilities designed to suit almost any conceivable business need. Examples of cloud computing capabilities and diversity include the following:
- Google Docs, Microsoft 365. Users can access Google Docs and Microsoft 365 via the internet. Users can be more productive because they can access work presentations and spreadsheets stored in the cloud anytime from anywhere on any device.
- Email, Calendar, Skype, WhatsApp. Emails, calendars, Skype and WhatsApp take advantage of the cloud's ability to provide users with access to data remotely so they can examine their data on any device, whenever and wherever they want.
- Zoom. Zoom is a cloud-based software platform for video and audio conferencing that records meetings and saves them to the cloud, letting users access them anywhere and at any time. Another common communication and collaboration platform is Microsoft Teams.
- AWS Lambda. Lambda lets developers run code for applications or back-end services without having to provision or manage servers. The pay-as-you-go model constantly scales with an organization to accommodate real-time changes in data usage and data storage. Other examples of major cloud providers that also support serverless computing capabilities include Google Cloud Functions and Microsoft Azure Functions.
- Salesforce. Salesforce is a cloud-centric customer relationship management platform designed to assist businesses in overseeing their sales, marketing and customer service operations.
Cloud computing use cases
How is the cloud actually used? The myriad services and capabilities found in modern public clouds have been applied across countless use cases, such as the following:
- Testing and development. Ready-made, tailored environments can expedite timelines and milestones.
- Production workload hosting. Organizations are using the public cloud to host live production workloads. This requires careful design and architecture of cloud resources and services needed to create an adequate operational environment for the workload and its required level of resilience.
- Big data analytics. Remote data centers through cloud storage are flexible and scalable and can provide valuable data-driven insights. Major cloud providers offer services tailored to big data analytics and projects, such as Amazon EMR and Google Cloud Dataproc.
- IaaS. IaaS lets companies host IT infrastructures and access compute, storage and network capabilities in a scalable manner. Pay-as-you-go subscription models are cost-effective, as they can help companies save on upfront IT costs.
- PaaS. PaaS can help companies develop, run and manage applications more easily and flexibly, at a lower cost than maintaining a platform on premises. PaaS services can also increase the development speed for applications and enable higher-level programming.
- Hybrid cloud. Organizations have the option to use the appropriate cloud -- private or public -- for different workloads and applications to optimize cost and efficiency according to the circumstance.
- Multi-cloud. Using multiple different cloud services from separate cloud providers can help subscribers find the best cloud service fit for diverse workloads with specific requirements.
- Storage. Large amounts of data can be stored remotely and accessed easily. Clients only have to pay for storage that they actually use.
- Disaster recovery. Cloud offers faster recovery than traditional on-premises DR. Furthermore, it's offered at lower costs.
- Data backup. Cloud backup options are generally easier to use. Users don't have to worry about availability and computing capacity, and the cloud provider manages data security.
- Artificial intelligence as a service. Cloud computing lets individuals without formal knowledge or expertise in data sciences reap the benefits of AIaaS. For example, a web developer might create a facial recognition app with their web development skills. AI is available as a service in the cloud and accessible via the API. This lets users automate routine tasks, saving time and personnel costs. Businesses can also enhance decision-making by using AI to predict outcomes based on historical datasets.
- Internet of things. Cloud computing simplifies the processing and management of data from IoT devices. Cloud platforms offer the scalability and processing capacity required to handle the enormous amounts of data produced by IoT devices, facilitating real-time analytics and decision-making. For example, an IoT device system such as Google Nest or Amazon Alexa can collect data on how much energy is used inside a smart home. The device can then use cloud computing to analyze the gathered data and make recommendations to the homeowner on how to reduce energy consumption.
Cloud computing vs. traditional web hosting
Given the many different services and capabilities of the public cloud, there has been some confusion between cloud computing and major uses, such as web hosting. While the public cloud is often used for web hosting, the two are quite different. Significant innovations in virtualization and distributed computing, as well as improved access to high-speed internet, have accelerated interest in cloud computing.
The distinct characteristics of cloud computing that differentiate it from traditional web hosting include the following:
- With cloud computing, users can access large amounts of computing power on demand. It's typically sold by the minute or the hour. With traditional hosting, users typically pay for a set amount of storage and processing power. Since resources are limited, businesses can look into virtual private servers or dedicated hosting as their business and demands grow.
- Cloud computing is elastic, meaning users can have as much or as little of a service as they want at any given time. However, with traditional hosting, scalability is often constrained, particularly in shared hosting. Shared hosting involves multiple websites sharing resources on a single server, potentially causing performance issues and slower website speeds if one site encounters a sudden surge in traffic.
- Service is fully managed by the provider on cloud computing platforms; the consumer needs nothing but a PC and internet access. While shared traditional hosting is also fully managed by the provider, typically users are required to control their website from a user-friendly interface such as cPanel.
- In comparison to traditional hosting, cloud hosting is more reliable. Cloud providers maintain redundant infrastructure and operate across numerous data centers, reducing downtime and increasing availability. Traditional hosting, on the other hand, is based on a single server, making it more prone to hardware failures and higher downtime threats.
- Both cloud hosting and traditional hosting entail security considerations. Cloud hosting providers invest significantly in security measures to safeguard data and infrastructure. However, certain organizations might find traditional hosting more suitable, as it provides greater control over security measures and can accommodate specific security requirements.
Cloud computing service providers
The cloud service market has no shortage of providers. The three largest public CSPs -- AWS, GCP and Microsoft Azure -- have established themselves as dominant players in the industry. According to the Synergy Research Group, at the end of 2022, these three vendors made up 66% of the worldwide cloud infrastructure market.
Other major CSPs include the following:
- Alibaba.
- Citrix.
- IBM.
- Oracle.
- Rackspace.
- Salesforce.
- SAP.
- VMware.
When selecting a cloud service vendor, organizations should consider certain things. First, the actual suite of services can vary between providers, and business users must select a provider offering services -- such as big data analytics or AI services -- that support the intended use case.
Though cloud services typically rely on a pay-per-use model, different providers often have variations in their pricing plans to consider. Furthermore, if the cloud provider will be storing sensitive data, an organization should also consider the physical location of the provider's servers.
Naturally, reliability and security should be top priorities. A provider's service-level agreement should specify a level of service uptime that's satisfactory to client business needs. When considering different cloud vendors, organizations should pay close attention to what technologies and configuration settings are used to secure sensitive information.
Cloud computing security
Security remains a primary concern for businesses contemplating cloud adoption -- especially public cloud adoption. Public CSPs share their underlying hardware infrastructure between numerous customers, as the public cloud is a multi-tenant environment. This environment demands significant isolation between logical compute resources. At the same time, access to public cloud storage and compute resources is guarded by account login credentials.
Many organizations bound by complex regulatory obligations and governance standards are still hesitant to place data or workloads in the public cloud for fear of outages, loss or theft. However, this resistance is fading, as logical isolation has proven reliable and the addition of data encryption and various identity and access management tools have improved security within the public cloud.
Ultimately, the responsibility for establishing and maintaining a secure cloud environment falls to the individual business user who is responsible for building the workload's architecture -- the combination of cloud resources and services in which the workload runs -- and using the security features that the cloud provider offers.
History of cloud computing
The history and evolution of cloud computing date back to the 1950s and 1960s.
- 1950s. Companies started using large mainframe computers, but due to the expense, not every organization could afford to purchase one. So, during the late 1950s and early 1960s, a process called time sharing was developed to make more efficient use of expensive processor time on the central mainframe. Time sharing lets users access numerous instances of computing mainframes simultaneously, maximizing processing power and minimizing downtime. This idea represents the first use of shared computing resources, the foundation of modern cloud computing.
- 1960s. The origins of delivering computing resources using a global network are, for the most part, rooted in 1969 when American computer scientist J.C.R. Licklider helped create the Advanced Research Projects Agency Network, the so-called precursor to the internet. Licklider's goal was to connect computers across the globe in a way that would let users access programs and information from any location.
- 1970s. Cloud computing began to take a more tangible shape with the introduction of the first VMs, letting users run more than one computing system within a single physical setup. The functionality of these VMs led to the concept of virtualization, which had a major influence on the progress of cloud computing.
- 1980s. In the 1970s and 1980s, Microsoft, Apple and IBM developed technologies that enhanced the cloud environment and advanced the use of cloud server and server hosting.
- 1990s. In 1999, Salesforce became the first company to deliver business applications from a website.
- 2000s. In 2006, Amazon launched AWS, providing services like computing and storage in the cloud. Following suit, the other major tech players, including Microsoft and Google, launched their own cloud offerings to compete with AWS.
- 2010s. Microsoft launched Azure in 2010 and Office 365 in 2011. Also, the Docker container technology was first released in this decade. Microservices and serverless platforms were also introduced in this timeframe when the Google App Engine was launched in 2008, followed by AWS Lambda in 2015.
- 2020 and beyond. The growth of serverless computing is anticipated to continue and edge computing will become more and more significant in the upcoming years. Edge computing devices are expected to improve and become more interconnected as AI and machine learning technologies advance.

Future of cloud computing and emerging technologies
Cloud computing is expected to see substantial breakthroughs and the adoption of new technologies. Back in its "2020 Data Attack Surface Report," Arcserve predicted that there will be 200 zettabytes of data stored in the cloud by 2025.
Some major trends and key points that are shaping the future of cloud computing include the following:
- Organizations are increasingly migrating mission-critical workloads to public clouds. One reason for this shift is that business executives who want to ensure that their companies can compete in the new world of digital transformation are demanding the public cloud.
- Business leaders are also looking to the public cloud to take advantage of its elasticity, modernize internal computer systems, and empower critical business units and their DevOps teams. Cloud providers, such as IBM and VMware, are concentrating on meeting the needs of enterprise IT, in part by removing the barriers to public cloud adoption that caused IT decision-makers to shy away from fully embracing the public cloud previously.
- Generally, when contemplating cloud adoption, many enterprises have mainly focused on new cloud-native applications -- that is, designing and building applications specifically intended to use cloud services. They haven't been willing to move their most mission-critical apps into the public cloud. However, these organizations are beginning to realize that the cloud is ready for the enterprise if they select the right cloud platforms.
- Cloud providers are locked in ongoing competition for cloud market share, so the public cloud continues to evolve, expand and diversify its range of services. This has resulted in public IaaS providers offering more than common compute and storage instances. For example, serverless, or event-driven, computing is a cloud service that executes specific functions, such as image processing and database updates. Traditional cloud deployments require users to establish a compute instance and load code into that instance. Then, the user decides how long to run -- and pay for -- that instance. With serverless computing, developers simply create code and the cloud provider loads and executes that code in response to real-world events so users don't have to worry about the server or instance aspect of the cloud deployment. Users only pay for the number of transactions that the function executes. AWS Lambda, Google Cloud Functions and Azure Functions are examples of serverless computing services.
- Public cloud computing also lends itself well to big data processing, which demands enormous compute resources for relatively short durations. Cloud providers have responded with big data services, including Google BigQuery for large-scale data warehousing and Microsoft Azure Data Lake Analytics for processing huge data sets.
- Another crop of emerging cloud technologies and services relates to AI and machine learning. These technologies provide a range of cloud-based, ready-to-use AI and machine learning services for client needs. Examples of these services include Amazon Machine Learning, Amazon Lex, Amazon Polly, Google Cloud Machine Learning Engine and Google Cloud Speech API.
- The connection between blockchain and cloud computing is poised to strengthen, as companies recognize blockchain's potential to improve operational efficiency, security and transparency. This trend is further supported by increased investment and the expansion of blockchain-as-a-service platforms.
When contemplating a move to the cloud, businesses must assess key factors such as latency, bandwidth, quality of service and security. Explore the top five network requirements for effective cloud computing.




