AWS data lake and data warehouse options for the cloud
Get ready for data analytics in the cloud. Learn the best ways to handle your data on AWS. Distinguish between data lakes and data warehouse services on AWS and how they work.
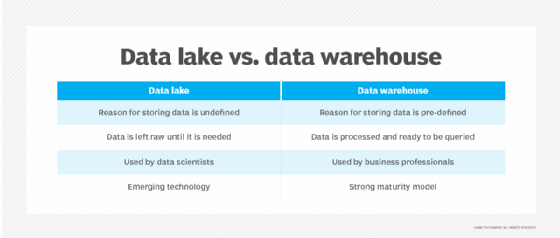
Enterprises exploring big data architectures have turned to data lakes and data warehouses for different types of analytic and AI workloads. These are complementary technologies -- data warehouses shine when you know what you want to analyze, while data lakes excel at combining data for unforeseen applications.
As these architectures migrate to the cloud, their core ideas evolve to take advantage of the various services of the cloud infrastructure. With data lakes, for example, raw data once housed in dedicated platforms such as Hadoop move to cloud object stores such as S3 that operate as a broad storage mechanism. Amazon takes advantage of this separation with architectural tiers that blend the best of AWS data lake and data warehouse capabilities with tools like Amazon Redshift Spectrum.
Data warehouses vs. data lakes
Enterprises typically turn to data lakes or data warehouses to generate value from data, but for different reasons. "Data lakes are best when an organization doesn't have a strict definition of analytics usage," said Justin Richie, data science director at Nerdery, an IT consultancy.
On the other hand, data warehouses are best when an organization has explicitly defined business logic, because it is difficult to change logic after schema creation. However, data lakes and data warehouses are not mutually exclusive, and an organization can use them in tandem, to obtain their individual benefits for the highest ROI.
Data lakes make it easy to store any kind of data, which is useful to accommodate unexpected workloads. Most AWS data lakes likely start with S3, an object storage service. "Object storage is a great fit for unstructured data," said Sean Feeney, cloud engineering practice director at Nerdery.
Data warehouses make it easier to manage structured data for existing analytics or common use cases. Amazon RedShift is the default choice for an AWS data warehouse to store structured, relational data.
AWS offers two services, Athena and Redshift Spectrum, to query unstructured data in S3. This provides a dynamic structure to run queries on objects, Feeney said.
Another aspect of a big data infrastructure involves the selection of services that move data around to support different types of workloads. Many AWS services pump data in and out of S3 and Redshift, including: DataSync, Database Migration Service, Kinesis, Storage Gateway, Snowball, Snowmobile, Data Pipeline and Glue.
Organizations use data lakes and data warehouses to ingest and analyze data.
Start with the end in mind
Ultimately, both AWS data lake and data warehouse services help to speed the development of different kinds of data analytics. Organizations should start with an end goal in mind for their big data analytics strategies, which will help shape their choices around AWS storage services.
Think about the different aspects of data systems in order to architect analytic applications on AWS, said Manoj Karanth, vice president and global head of data science and engineering for Mindtree, an IT consultancy. The first part involves data capture and data ingestion in its raw and basic cleansed format. The second part involves the creation of data views based on the data consumption.
For continuous data ingestion workloads, Glue is a great extract, transform and load (ETL) framework, Karanth said. When the data ingestion is event-based and infrequent, it can be more efficient to use a combination of AWS Lambda and AWS Step Functions to handle the processing and workflow aspects, respectively, he added.
Enterprises can store raw data in S3 to gain leeway in choosing the data consumption service that best fits their needs. Amazon Aurora and Relational Database Service are good choices for basic query handling, while Redshift is better for BI reporting that involves a lot of aggregation and good performance, Karanth said. He also sees Athena starting to provide similar, if not more performant query execution in many scenarios.
In the end, cost per insight is the best way to select the right AWS offering, Karanth said. Organizations can help manage costs by keeping the storage independent from cloud services used for analytics, he added.
Lake Formation vs. Redshift
Erik Gfesser
AWS Lake Formation and Amazon Redshift don't compete in the traditional sense, as Redshift can be integrated with Lake Formation, but you can't swap these two services interchangeably, said Erik Gfesser, principal architect at SPR, an IT consultancy.
Lake Formation, which became generally available in August 2019, is an abstraction layer on top of S3, Glue, Redshift Spectrum and Athena that offers a separately permissioned data catalog and blueprints for data ingestion to S3 from various sources. Lake Formation is a good place to start, Feeney said, if you're building a new data lake on AWS or need a data access management layer separate from the underlying data stores themselves.
Redshift is the native option to build a traditional relational data warehouse. It's a relational database service intended as a data warehouse for analytical workloads that involve petabyte volumes of data and read-intensive queries for reporting and visualizations against this data. Lake Formation can load data to Redshift for these purposes.
Customers can use Redshift Spectrum in a similar manner as Amazon Athena to query data in an S3 data lake. It also enables them to join this data with data stored in Redshift tables to provide a hybrid approach to storage. This is a good option for enterprises that want the robust querying capabilities of Redshift but also want to get out of the cluster management business and embrace serverless, Feeney said.
Data integration options
Lake Formation coordinates with other existing services such as Redshift and provides previously unavailable conveniences, such as the ability to set up a secure data lake using S3, Gfesser said. Lake Formation blueprints provide streamlined, out-of-the-box patterns for common use cases, such as bulk and incremental data extraction from data sources.
Data lakes are best when an organization doesn't have a strict definition of analytics usage.
Justin RichieData science director at Nerdery
Lake Formation builds on the capabilities of AWS Glue, which consists of four components -- Data Catalog, Crawlers, Jobs and Workflows -- that collectively catalog and process inbound data from source systems.
Data Catalog is an Apache Hive Metastore-compatible catalog that stores metadata about data and can be used across multiple AWS and non-AWS services. With Crawlers, users can apply advanced programming logic to automate how this metadata is gathered as data is ingested. Workflows can be used to stitch together Lake Formation-compatible services. Glue Jobs can process and load data through Python shell scripts as well as Apache Spark ETL scripts. A Python shell job is good for generic tasks as part of a Workflow, whereas a Spark job uses a serverless Apache Spark environment, Gfesser said.
Redshift is more traditional
Data warehouses such as Redshift offer a more traditional approach to building big data applications. Redshift is a familiar environment for many development shops, offers out-of-the-box compatibility with many commercial products and enables more complex queries. However, Redshift generally requires more administration and downtime to scale as volume and query activity increases, and it works with fewer data formats than Athena, Gfesser said.
Additionally, users may not see increased performance using Redshift until large data volumes materialize -- and even then, query speed may disappoint when compared to Athena, Gfesser said.
"Even though Redshift Spectrum functionality overlaps with Athena, the cost is relatively higher than Athena, because use of Redshift Spectrum requires a Redshift cluster, whereas the cost of Athena is solely based on query volume," Gfesser said.
Users must load data from AWS data sources into Redshift, while Athena works with data already stored in S3. Redshift Spectrum does that too, but it is not as fully featured and likely won't make sense to use unless a customer's data already exists in Redshift tables.
How to get the best of AWS data lakes and data warehouses
Ideally, organizations use data lakes and data warehouses together. Data lakes are best suited as central repositories for ingesting data, and once business logic is defined, the data can be loaded into a data warehouse via the data lake.
Data lakes are the best choice for an organization that wants to build data pipelines, as they provide the necessary flexibility, efficiency and cost structures, said Ashish Thusoo, co-founder and CEO of Qubole, a cloud data platform provider. They also provide the most flexibility for data scientists and their machine learning models, which require a large amount of raw data.
Large enterprises often have one data lake and multiple data warehouses, because different business units use data in different ways. A data warehouse is the legacy method of data projects, and data lakes are a relative newcomer in the big-data movement. Many software providers sell both offerings. SQL development is often consistent across both data lakes and data warehouses, Nerdery's Richie said.
Organizations should start with a business intelligence report or chart built for pre-aggregated, gold-standard datasets, Thusoo said. As business users think of things to explore, they can work their way backwards to increasingly fine-grain or raw data on a need-to-know basis.
For example, business users may want to investigate why a company's sales dropped in a particular location and analyze different stages of the sales funnel to zero in on the issue. Often, this information is only available in the raw data that resides in their data lake, so access to this data avoids the costly process of transforming the data for a data warehouse.
Many firms have a data lake for their unstructured raw data and data warehouses for their more refined processed data, said Hannu Valtonen, vice-president of product at Aiven, a data infrastructure management tools provider. This approach enables faster and easier analytics, rather than transforming data from a data lake for a new use case from scratch, and preserves the whole raw history of that data for future use. Subsequent data processing is slower and more expensive compared with data that's already loaded into the data warehouse, since data scientists need to figure out what data they need, how to best format it and write algorithms to format the raw data.
Often data first enters an organization's systems through data lakes, and then some subset of that data is processed and sent to a data warehouse, with its meaning parsed and deciphered from the initial raw mass of data.
"As storage costs have rapidly gone down, keeping masses of data in its raw form in a data lake has become possible for more and more firms," Valtonen said. Moreover, organizations can keep the raw data indefinitely, waiting for the day when someone comes up with a new question they want answered.


 Erik Gfesser
Erik Gfesser







