Amazon Simple Storage Service (Amazon S3)
What is Amazon Simple Storage Service (Amazon S3)?
Amazon Simple Storage Service (Amazon S3) is a scalable, high-speed, web-based cloud storage service. The service is designed for online backup and archiving of data and applications on Amazon Web Services (AWS). Amazon S3 was designed with a minimal feature set and created to make web-scale computing easier for developers.
What are Amazon S3 features?
S3 provides 99.999999999% durability for objects stored in the service and supports multiple security and compliance certifications. An administrator can also link S3 to other AWS security and monitoring services, including CloudTrail, CloudWatch and Macie. There's also an extensive partner network of vendors that link their services directly to S3.
Data can be transferred to S3 over the public internet via access to S3 application programming interfaces (APIs). There's also Amazon S3 Transfer Acceleration for faster movement over long distances, as well as AWS Direct Connect for a private, consistent connection between S3 and an enterprise's own data center. An administrator can also use AWS Snowball, a physical transfer device, to ship large amounts of data from an enterprise data center directly to AWS, which will then upload it to S3. AWS Snowball Edge can be used to migrate tape storage to S2.
In addition, users can integrate other AWS services with S3. For example, an analyst can query data directly on S3 either with Amazon Athena for ad hoc queries or with Amazon Redshift Spectrum for more complex analyses.
S3 buckets can be mounted directly into a file system using various tools and plugins. Amazon Mountpoint is an example of these tools that is developed by Amazon. These tools translate file system requests into S3 API requests. This could allow S3 to be used with non-cloud-native tools. Care should be exercised when using these though; since S3 works on entire objects at one time, the performance or pricing might be impacted depending on the access characteristics of the application.
What are Amazon S3 use cases?
Amazon S3 can be used by organizations ranging in size from small businesses to large enterprises. S3's scalability, availability, security, and performance capabilities make it suitable for a variety of data storage use cases. Common use cases for S3 include the following:
- Data storage.
- Data archiving.
- Document storage.
- Application hosting for deployment, installation and management of web apps.
- Software delivery.
- Data backup.
- Disaster recovery (DR).
- Log file storage.
- Big data analytics tools on stored data.
- Data lakes and data warehouses.
- Mobile applications.
- Internet of things (IoT) devices.
- Media hosting for images, videos and music files.
- Software delivery.
- Website hosting -- particularly well-suited to work with Amazon CloudFront for content delivery.
How does Amazon S3 work?
Amazon S3 is an object storage service, which differs from other types of cloud computing storage types, such as block and file storage. Each object is stored as a file with its metadata included. The object is also given an ID number. Data is organized into buckets instead of folders. Applications use this ID number to access objects. This is unlike file and block cloud storage, where a developer can access an object via a representational state transfer API.
The S3 object storage cloud service gives a subscriber access to the same systems that Amazon uses to run its websites. S3 enables customers to upload, store and download practically any file or object that is up to 5 terabytes in size -- with the largest single upload capped at 5 gigabytes (GB).

What are Amazon S3's storage classes?
Amazon S3 comes in seven storage classes:
- S3 Standard is suitable for frequently accessed data that needs to be delivered with low latency and high throughput. S3 Standard targets applications, dynamic websites, content distribution and big data workloads.
- S3 Intelligent-Tiering is most suitable for data with access needs that are either changing or unknown. S3 Intelligent-Tiering has four different access tiers: Frequent Access, Infrequent Access (IA), Archive and Deep Archive. Data is automatically moved to the most inexpensive storage tier according to customer access patterns.
- S3 Standard-IA offers a lower storage price for data that is needed less often but that must be quickly accessible. This tier can be used for backups, DR and long-term data storage.
- S3 One Zone-IA is designed for data that is used infrequently but requires rapid access on the occasions that it is needed. Use of S3 One Zone-IA is indicated for infrequently accessed data without high resilience or availability needs, data that can be recreated and backed up on-premises data.
- S3 Glacier is the least expensive storage option in S3, but it is strictly designed for archival storage because it takes longer to access the data. Glacier offers variable retrieval rates that range from minutes to hours.
- S3 Glacier Deep Archive has the lowest price option for S3 storage. S3 Glacier Deep Archive is designed to retain data that only needs to be accessed once or twice a year.
- S3 Outposts adds S3 object storage features and APIs to an on-premises AWS Outposts environment. S3 Outposts is best used when performance needs call for data to be stored near on-premises applications or to satisfy specific data residency requirements.
A user can also implement lifecycle management policies to curate data and move it to the most appropriate tier over time.
Working with S3 buckets
Amazon does not impose a limit on the number of items that a subscriber can store; however, there are limits to Amazon S3 bucket quantities. Each AWS account allows up to 100 buckets to be created by default; limits can be increased to 1,000 by requesting service limit increases.
An Amazon S3 bucket exists within a particular region of the cloud. An AWS customer can use an Amazon S3 API to upload objects to a particular bucket. Customers can configure and manage S3 buckets.

Protecting S3 data
User data is stored on redundant servers in multiple data centers. S3 uses a simple web-based interface -- the Amazon S3 console -- and encryption for user authentication.
S3 buckets are kept private from public access by default, but an administrator can choose to make them publicly accessible. A user can also encrypt data before storage. Rights might be specified for individual users, who will then need approved AWS credentials to download or access a file in S3. Improperly secured S3 data has been a major source of data leaks.
S3 has strong data consistency. Object PUT requests are processed at the object level. If two PUT requests for one object are submitted, the one with the later timestamp will win. S3 does not natively support object locking for concurrent writes.
When a user stores data in S3, Amazon tracks the usage for billing purposes, but it does not otherwise access the data unless required to do so by law.
Amazon S3 is compliant with the Payment Card Industry Data Security Standard and the Health Insurance Portability and Accountability Act. When properly configured it can be used to handle credit card and health care data. It is also compatible with various other compliance programs.

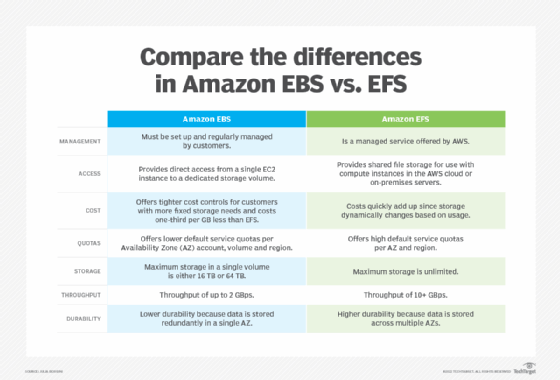
Amazon S3 vs. EBS vs. EFS
AWS offers several storage services. EBS and EFS are traditional file storage, while S3 is object storage.
Amazon Elastic Block Storage (EBS) is filesystem block storage intended to be used by an Amazon Elastic Compute Cloud (EC2) virtual machine (VM). EBS can be thought of as the hard drive on a computer. Usually, each EBS instance is only attached to one EC2 instance. EBS offers the highest read/write performance.
Amazon Elastic File System (EFS) is shared file storage that can be attached to several EC2 instances. This can be thought of as a shared drive that many computers have access to. The storage size of an EFS volume dynamically grows and shrinks as needed.
Amazon S3 is object storage. It is usually not attached to a VM, instead it is used by an application. For example, an application might send its logs to an S3 bucket, and another analytics application can then read the logs. S3 can also be queried, similar to a database, making it an excellent tool for data warehouses and data lakes.
Amazon S3 pricing
Amazon S3 pricing can be complicated to forecast. There is a charge for the storage, for the object access, and for data ingress/egress fees.
S3 storage pricing is charged by gigabyte per month. The price changes depending on the storage tier used or how often the data will be accessed. The readily available storage tiers might be pennies a GB a month. While the backup tiers take longer to retrieve but might be fractions of a cent a month per GB.
Data requests and retrievals are also charged by the API call. They are charged as fractions of a cent per 1,000 requests. Calls to find what data is there (GET, SELECT) are cheaper than calls to modify the data (PUT, COPY, POST, LIST). All calls to S3 are charged, including if an administrator wanted to look at a file list.
Additional data ingress and egress charges m be added to S3 calls. This is charged per GB transferred. The exact cost might depend on the amount transferred and the locations involved.
Amazon offers a simple pricing calculator to help organizations estimate their bill. Due to the complicated nature of the items and the usage billing, it can be difficult to forecast a new application's cost. It is important that the application be optimized for S3 to eliminate redundant calls and keep the cost down.

Competitor services to Amazon S3
Competitor services to Amazon S3 include other object storage software tool services. Major cloud service providers such as Google, Microsoft, IBM and Alibaba offer comparable object storage services. Main competitor services to Amazon S3 include the following:
- Google Cloud Storage.
- Azure Blob storage.
- IBM Cloud Object Storage.
- DigitalOcean Spaces.
- Alibaba Cloud Object Storage Service.
- Cloudian.
- Zadara Storage.
- Oracle Cloud Infrastructure Object Storage.
Explore top AWS storage types for file, block, object and how to use S3-compatible storage. Check out the top five Amazon S3 storage security best practices.






