
cloud disaster recovery (cloud DR)
What is cloud disaster recovery (cloud DR)?
Cloud disaster recovery (cloud DR) is a combination of strategies and services intended to back up data, applications and other resources to public cloud or dedicated service providers. When a disaster occurs, the affected data, applications and other resources can be restored to the local data center -- or a cloud provider -- to resume normal operation for the enterprise.
The goal of cloud DR is virtually identical to traditional DR: to protect valuable business resources and ensure protected resources can be accessed and recovered to continue normal business operations.
Importance of cloud DR
DR is a central element of any business continuity (BC) strategy. It entails replicating data and applications from a company's primary infrastructure to a backup infrastructure, usually situated in a distant geographical location.
Before the advent of cloud connectivity and self-service technologies, traditional DR options were limited to local DR and second-site implementations. Local DR didn't always protect against disasters such as fires, floods and earthquakes. A second site -- off-site DR -- provided far better protection against physical disasters, but implementing and maintaining a second data center imposed significant business costs.
With the emergence of cloud technologies, public cloud and managed service providers could create a dedicated facility to offer a wide range of effective backup and DR services and capabilities.
The following reasons highlight the importance of cloud storage and disaster recovery:
- Cloud DR ensures business continuity in the event of natural disasters and cyber attacks, which can disrupt business operations and result in data loss.
- With a cloud disaster recovery strategy, critical data and applications can be backed up to a cloud-based server. This enables quick data recovery for businesses in the wake of an event, thus reducing downtime and minimizing the effects of the outage.
Cloud-based DR offers better flexibility, reduced complexities, more cost-effectiveness and higher scalability compared with traditional DR methods. Businesses receive continuous access to highly automated, highly scalable, self-driven off-site DR services without the expense of a second data center and without the need to select, install and maintain DR tools.
Selecting a cloud DR provider
An organization should consider the following five factors when selecting a cloud DR provider:
- Distance. A business must consider the cloud DR provider's physical distance and latency. Putting DR too close increases the risk of shared physical disaster, but putting the DR too far away increases latency and network congestion, making it harder to access DR content. Location can be particularly tricky when the DR content must be accessible from numerous global business locations.
- Reliability. Consider the cloud DR provider's reliability. Even a cloud experiences downtime, and service downtime during recovery can be equally disastrous for the business.
- Scalability. Consider the scalability of the cloud DR offering. It must be able to protect selected data, applications and other resources. It must also be able to accommodate additional resources as needed and provide adequate performance as other global customers use the services.
- Security and compliance. It's important to understand the security requirements of the DR content and be sure the provider can offer authentication, virtual private networks, encryption and other tools needed to safeguard the business's valuable resources. Evaluate compliance requirements to ensure the provider is certified to meet compliance standards that relate to the business, such as ISO 27001, SOC 2 and SOC 3, and Payment Card Industry Data Security Standard (PCI DSS).
- Architecture. Consider how the DR platform must be architected. There are three fundamental approaches to DR, including cold, warm and hot disaster recovery. These terms loosely relate to the ease with which a system can be recovered.
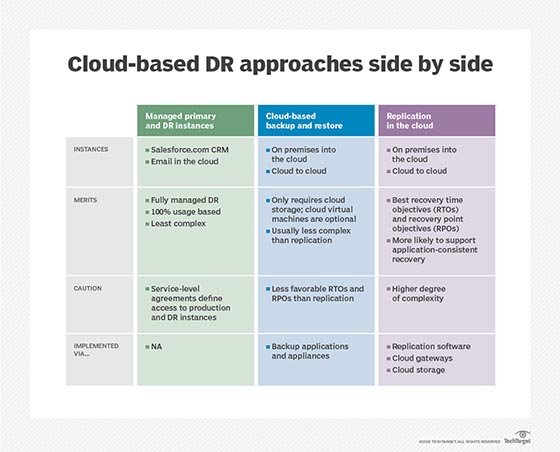
Approaches to cloud DR
The following are the three main approaches to cloud disaster recovery:
- Cold DR typically involves storage of data or virtual machine (VM) images. These resources generally aren't usable without additional work such as downloading the stored data or loading the image into a VM. Cold DR is usually the simplest approach -- often just data storage -- and the least expensive approach, but it takes the longest to recover, leaving the business with the longest downtime in a disaster.
- Warm DR is generally a standby approach where duplicate data and applications are placed with a cloud DR provider and kept up to date with data and applications in the primary data center. But the duplicate resources aren't doing any processing. When disaster strikes, the warm DR can be brought online to resume operations from the DR provider -- often a matter of starting a VM and redirecting IP addresses and traffic to the DR resources. Recovery can be quite short, but still imposes some downtime for the protected workloads.
- Hot DR is typically a live parallel deployment of data and workloads running together in tandem. That is, both the primary data center and the DR site use the same workload and data running in synchronization -- both sites sharing part of the overall application traffic. When disaster strikes one site, the remaining site continues without disruption to handle the work. Users are ideally unaware of the disruption. Hot DR has no downtime, but it can be the most expensive and complicated approach.
It's possible to mix approaches, enabling higher-priority workloads to employ a hot approach while lower-priority workloads or data sets use a warm or even cold approach. However, it's important for organizations to determine the best approach for each workload or resource and to identify a cloud DR provider that can adequately support the desired approaches.
Benefits of cloud DR
Cloud DR and backups provide several benefits when compared with more traditional DR strategies:
Pay-as-you-go options. Organizations that deploy do-it-yourself DR facilities face significant capital costs while engaging managed colocation providers for off-site DR services that often lock organizations into long-term service agreements. A major advantage of cloud services is the pay-as-you-go model, which enables organizations to pay a recurring monthly charge only for the resources and services they use. As resources are added or removed, the payments change accordingly.
In effect, the cloud model of service delivery turns upfront capital costs into recurring operational expenses. However, cloud providers frequently offer discounts for long-term resource commitments, which can be more attractive to larger organizations with static DR needs.
Flexibility and scalability. Traditional DR approaches, usually implemented in local or remote data centers, often impose limitations in flexibility and scalability. The business must buy the servers, storage, network gear and software tools needed for DR, and then design, test and maintain the infrastructure needed to handle DR operations -- substantially more if the DR is directed to a second data center. This typically represents a major capital and recurring expense for the business.
Cloud DR options, such as public cloud services and disaster recovery as a service (DRaaS), can deliver enormous amounts of resources on demand, enabling businesses to engage as many resources as necessary -- usually through a self-service portal -- and then adjust those resources when business demands change, such as when new workloads are added or old workloads and data are retired.
High reliability and geo-redundancy. One essential hallmark of a cloud provider is a global footprint, ensuring multiple data centers support users across major global geopolitical regions. Cloud providers use this to improve service reliability and ensure redundancy. Businesses can readily take advantage of geo-redundancy to place DR resources in another region -- or even multiple regions -- to maximize availability. The quintessential off-site DR scenario is a natural trait of the cloud.
Easy testing and fast recovery. Cloud workloads routinely operate with VMs, making it easy to copy VM image files to in-house test servers to validate workload availability without affecting production workloads. In addition, businesses can select options with high bandwidth and fast disk input/output to optimize data transfer speeds in order to meet recovery time objective (RTO) requirements. However, data transfers from cloud providers impose costs, so testing should be performed with those data movement -- cloud data egress -- costs in mind.
Not bound to the physical location. With a cloud DR service, organizations can choose to have their backup facility situated virtually anywhere in the world, far away from the organization's physical location. This provides added protection against the possibility that a disaster might jeopardize all servers and pieces of equipment located inside the physical building.
Drawbacks of cloud DR
The following are some drawbacks of cloud DR:
- Complexity. Setting up and maintaining cloud disaster recovery can be challenging and require specialized expertise.
- Internet connectivity. Cloud DR needs consistent internet access, which might be difficult in places with poor internet connectivity.
- Migration cost. Transferring large volumes of data to the cloud can be expensive.
- Security and privacy concerns. With cloud DR, there's always the danger of user data getting into the hands of unauthorized personnel, since cloud providers have access to customer data. This can sometimes be avoided by opting for zero-knowledge providers that maintain a high level of confidentiality.
- Vendor lock-in. Once the data is migrated to a cloud-based DR service, it can be difficult for organizations to avoid vendor lock-in or switch to another provider.
- Dependence on third-party providers. As with any third-party vendor, there's a risk of dependence on their service and a loss of control over the disaster recovery process.
Cloud DR vs. traditional DR
Cloud-based DR services and DRaaS offerings can provide cost benefits, flexibility and scalability, geo-redundancy, and fast recovery. But cloud DR might not be appropriate for all organizations or circumstances.
The following are a few situations where more traditional DR approaches might be beneficial, even essential, for the business:
- Compliance requirements. Cloud services are increasingly acceptable for enterprise usage where well-established regulatory oversight is required, such as the Health Insurance Portability and Accountability Act and PCI DSS. However, some organizations might still face prohibitions when storing certain sensitive data outside an immediate data center -- or in any resource or infrastructure that isn't under the organization's direct control, such as a public cloud, which is a third-party infrastructure. In these cases, the business could be obligated to implement local or owned off-site DR to satisfy security and compliance demands.
- Limited connectivity. Cloud resources and services depend on wide area network connectivity such as the internet. DR use cases put a premium on connectivity because a reliable, high-bandwidth connection is critical for quick uploads, synchronization and fast recovery. Although reliable, high-bandwidth connectivity is common in global urban and most suburban areas, it's hardly universal. Remote installations such as edge computing sites often exist -- at least, in part -- because of limited connectivity, so it might make perfect sense to implement data backups, workload snapshots and other DR techniques at local sites where connectivity is questionable. Otherwise, the business risks data loss and problematic RTOs.
- Optimum recovery. Clouds offer powerful benefits, but users are limited to the infrastructure, architecture and tools that the cloud provider offers. Cloud DR is constrained by the provider and the service-level agreement. In some cases, the recovery point objective (RPO) and RTO offered by the cloud DR provider might not be adequate for the organization's DR needs -- or the service level might not be guaranteed. By owning the DR platform in house, a business can implement and manage a custom DR infrastructure that can best guarantee DR performance requirements.
- Use existing investments. DR needs have been around much longer than cloud services, and legacy DR installations -- especially in larger businesses or where costs are still being amortized -- might not be so easily displaced by newer cloud DR offerings. That is, a business that already owns the building, servers, storage and other resources might not be ready to abandon that investment. In these cases, the business can adopt cloud DR more slowly and cautiously, systematically adding workloads to the cloud DR provider as an avenue of routine technology refresh, rather than spending another round of capital.
It's worth noting that choosing between traditional DR and cloud DR isn't mutually exclusive. Organizations might find that traditional DR is best for some workloads, while cloud DR can work quite well for other workloads. Both alternatives can be mixed and matched to provide the best DR protection for each of the organization's workloads.
Cloud disaster recovery and business continuity
The terms business continuity and disaster recovery -- together referred to as BCDR or BC/DR -- describe a collection of procedures and methods that can be used to aid an organization's recovery from a disaster and the continuation or restart of regular business activities.
Business continuity
BC basically refers to the plans and technologies put in place to ensure business operations can resume with minimum delay and difficulty following the onset of an incident that could disrupt the business.
By this definition, BC is a broad topic area that involves a multitude of subjects including security, business governance and compliance, risk assessment and management, change management, and disaster preparedness and recovery. For example, BC efforts might consider and plan for a broad range of catastrophes such as epidemics, earthquakes, floods, fires, service outages, physical or cyber attacks, theft, sabotage, and other potential incidents.
BC planning typically starts with risk recognition and assessment: What risks is the business planning for, and how likely are those risks? Once a risk is understood, business leaders can design a plan to address and mitigate the risk. The plan is budgeted, procured and implemented. Once implemented, the plan can be tested, maintained and adjusted as required.
Disaster recovery
Disaster recovery, which also includes cloud-based DR, is part of a broader BC umbrella. It typically plays a central role in many avenues of BC planning, such as for floods, earthquakes and cyber attacks. For example, if the business operates on a known earthquake fault, the risk of damage from an earthquake would pose a potential risk that would be analyzed to formulate a mitigation plan. Part of the mitigation plan might be to adopt cloud DR in the form of a second hot site located in a region free of earthquake danger.
Thus, the BC plan would rely on redundancy of the cloud DR service to seamlessly continue operations in the event that the primary data center became unavailable, continuing business operations. In this example, DR would only be a small part of the BC plan, with additional planning detailing corresponding changes in workflows and job responsibilities to maintain normal operations -- such as taking orders, shipping products and handling billing -- and work to restore the affected resources.
Creating a cloud-based disaster recovery plan
Building a cloud DR plan is virtually identical to more traditional local or off-site disaster recovery plans. The principal difference between cloud DR and more traditional DR approaches is the use of cloud technologies and DRaaS to support an appropriate implementation. For example, rather than backing up an important data set to a different disk in another local server, cloud-based DR would back up the data set to a cloud resource such as an Amazon Simple Storage Service bucket. As another example, instead of running an important server as a warm VM in a colocation facility, the warm VM could be run in Microsoft Azure or through any number of different DRaaS providers. Thus, cloud DR doesn't change the basic need or steps to implement DR, but rather provides a new set of convenient tools and platforms for DR targets.
There are three fundamental components of a cloud-based disaster recovery plan: analysis, implementation and testing.
Analysis. Any DR plan starts with a detailed risk assessment and analysis, which basically examines the current IT infrastructure and workflows, and then considers the potential disasters that a business is likely to face. The goal is to identify potential vulnerabilities and disasters -- everything from intrusion vulnerabilities and theft to earthquakes and floods -- and then evaluate whether the IT infrastructure is up to those challenges.
An analysis can help organizations identify the business functions and IT elements that are most critical and predict the potential financial effects of a disaster event. Analysis can also help determine RPOs and RTOs for infrastructure and workloads. Based on these determinations, a business can make more informed choices about which workloads to protect, how those workloads should be protected and where more investment is needed to achieve those goals.
Implementation. The analysis is typically followed by a careful implementation that details steps for prevention, preparedness, response and recovery. Prevention is the effort made to reduce possible threats and eliminate vulnerabilities. This might include employee training in social engineering and regular operating system updates to maintain security and stability. Preparedness involves outlining the necessary response -- who does what in a disaster event. This is fundamentally a matter of documentation. The response outlines the technologies and strategies to implement when a disaster occurs. This preparedness is matched with the implementation of corresponding technologies, such as recovering a data set or server VM backed up to the cloud. Recovery details the success conditions for the response and steps to help mitigate any potential damage to the business.
The goal here is to determine how to address a given disaster, should it occur, and the plan is matched with the implementation of technologies and services built to handle the specific circumstances. In this case, the plan includes cloud-based technologies and services.
Testing. Any DR plan must be tested and updated regularly to ensure IT staff are proficient at implementing the appropriate response and recovery successfully and in a timely manner, and that recovery takes place within an acceptable time frame for the business. Testing can reveal gaps or inconsistencies in the implementation, enabling organizations to correct and update the DR plan before a real disaster strikes.
Cloud disaster recovery providers, vendors
At its heart, cloud DR is a form of off-site DR. An off-site strategy enables organizations to guard against incidents within the local infrastructure, and then either restore the resources to the local infrastructure or continue running the resources directly from the DR provider. Consequently, countless vendors have emerged to provide off-site DR capabilities.
The most logical avenue for cloud DR is through major public cloud providers. For example, AWS offers the CloudEndure Disaster Recovery service, Microsoft Azure provides Azure Site Recovery, and Google Cloud Platform offers Cloud Storage and Persistent Disk options for protecting valued data. Enterprise-class DR infrastructures can be architected within all three major cloud providers.
Beyond public clouds, an array of dedicated DR vendors now offers DRaaS products, essentially providing access to dedicated clouds for DR tasks.
DRaaS providers and their products include the following:
- Bluelock.
- Expedient.
- IBM Cloud Disaster Recovery.
- Iland.
- Recovery Point Systems.
- Sungard Availability Services.
- TierPoint.
- VMware Site Recovery Manager.
In addition, more traditional backup vendors now have DRaaS offerings:
- Acronis.
- Arcserve Unified Data Protection.
- Carbonite.
- Databarracks.
- Datto.
- Unitrends.
- Zerto.
Given the proliferation of DRaaS offerings, it's critical for organizations to evaluate each potential offering for factors such as reliability, recurring costs, ease of use and provider support. Any DR platform must be updated and tested regularly to ensure DR is available and will function as expected.
To ensure data center operations can be resumed as fast and effectively as possible after an incident, organizations should create a complete checklist for disaster recovery planning. Examine the 12 essential elements of a disaster recovery plan checklist.






