What are microservices? Everything you need to know
Microservices, or microservices architecture, is an approach to the design and implementation of enterprise applications in which a large application is built from modular components or services.
Each module supports a specific task or business goal and uses a well-defined communications interface, such as an application programming interface (API), to communicate with other modules and services. A microservices architecture makes extensive use of virtual container and networking technologies, and is noted for its streamlined module development, deployment and scalability -- characteristics that are particularly well-suited to application development for modern public clouds.
A microservices architecture is a significant departure from traditional monolithic application architectures where all major features and functions of the application are coded into a single executable application. Software developer and author Martin Fowler is credited with promoting the idea of breaking down services in a service-oriented architecture (SOA) into microservices.
How do microservices work?
In a microservices architecture, an application is divided into distinct tasks and services. Each task or service is created independently, and each one runs a unique process and usually manages its own database. A service can generate alerts, log data, support user interfaces (UIs), handle user identification or authentication, and perform various other computing and processing tasks.
By comparison, a traditional monolithic architecture might comprise the same fundamental assortment of tasks and services needed to accomplish the application's purpose. But those functions are all contained within a single, large, all-in-one executable application. A microservices application can be designed and assembled to perform many of the same jobs previously performed by monolithic application designs.
The microservices paradigm provides development teams with a more decentralized approach to building software. Each service can be isolated, rebuilt, tested, redeployed and managed independently. For example, if a program isn't properly generating reports, IT staff can trace the problem to a specific service and then test, restart, patch and redeploy that service as needed, independent of other services.
Microservices architecture and design characteristics
Microservices architecture consists of discrete components and services; their intercommunication and data exchanges create the functions of a complete application. Typical characteristics of a microservices design and architecture include the following:
- Unique components. Services are designed and deployed as individual components working together to accomplish a specific function or address a specific requirement.
- Decentralized. Unique microservices components have few if any dependencies, although loose coupling requires frequent and extensive communication between components.
- Resilient. Services are designed for maximum fault tolerance. A single service failure shouldn't disable an entire application. This often requires excellent software design and site reliability engineering (SRE) practices, as well as redundant deployment and failover and high scalability techniques.
- API-based. A microservices architecture relies on APIs and API gateways to facilitate communication between components and other applications.
- Data separation. Each service accesses its own database or storage volume.
- Automation. Microservices application components can be many -- and can be cumbersome to deploy manually. Microservices rely on automation and orchestration technologies for component deployment and scaling.
Benefits of a microservices architecture
Microservices designs and deployments have grown thanks to the cloud, containerization and hyperconnected systems. A microservices architecture offers several advantages:
- Independence. Every microservice module or service can be developed using different languages and tools and deployed on different platforms. The only connection between microservices components is the API through which they communicate across a network. This brings flexibility to application development.
- Lifecycles. That development and deployment independence means different development teams commonly build and maintain microservices components through continuous integration and continuous development (CI/CD) pipelines. This offers more development agility and can enhance time to market. It also reduces testing time and requirements because only the module is tested -- there is little, if any, need to regression test the entire application.
- Isolation. Since each component of a microservices application operates independently, it's far easier to monitor the health and performance of each component and oversee the operation of the greater application. This isolation also makes it easier to identify and remediate faults such as restarting a failed module.
- Scalability. To scale a traditional monolithic application, IT staff must deploy a new copy of the entire application. With a microservices application, only the associated components must scale. It's faster and far less resource-intensive to deploy and load balance a few containers rather than an entire monolithic application.
- Speed. Each microservices component is small, letting developers design, code, test and update a component in far less time than a traditional monolithic application design.
- Reusability. Modular application components are reusable by other applications, further easing application design investments and speeding development timeframes.
- Container compatibility. Microservices components are suited for deployment and management within virtual containers, using well-proven container and orchestration technologies such as Docker and Kubernetes.
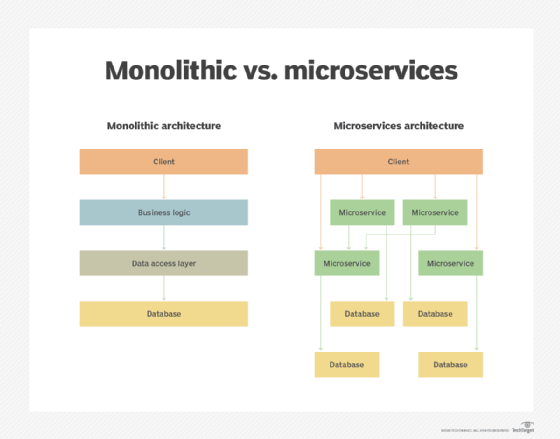
Microservices vs. monolithic architecture
A monolithic architecture is a single program. It incorporates all the application or operational logic required to perform work within a single cohesive stack located on a single principal server within the data center. This has always been a logical and memory-efficient way to build applications, but it's inadequate for many modern application and business needs. Let's compare the tradeoffs of monolithic vs. microservices architectures.
Key differences
Monolithic applications are considered all-in-one entities where the entire application is built, tested and deployed as a single codebase. Users access the application through the client-side application interface or presentation layer. User interactions and queries are exchanged in accordance with underlying application and business logic, which dictate database access, data processing and how results are returned to the client. No monolithic application exists or runs without dependencies -- it's just that most of the application's specific "work" is performed within a single software entity.
A microservices architecture decomposes underlying logic into a series of different tasks or services, each of which can be developed and deployed separately and communicate through an API. Users interact with the application via a client-side app or web portal; the interface distributes client requests to corresponding services and returns results to the user. A microservices application also involves dependencies such as a common operating system (OS) kernel, container orchestration engines and database access credentials.
Pros vs. cons
Monolithic architecture designs aren't necessarily complex, but building complex applications with many integration points on a monolithic architecture introduces many possible points of failure, such as software bugs or hardware faults, that could result in extended downtimes and human intervention. Monolithic applications are large and time-consuming to code, build and test. Monolithic applications also don't scale well. For example, if an application requires more computing power to handle a spike in user requests, a new instance of that application -- and all its dependencies -- must be deployed on another server.
At scale, microservices provide a level of efficiency that traditional monolithic applications can't. When a microservices function requires more computing power, only that microservice is scaled by adding more instances of that service through a load balancer to share network traffic. In addition, orchestration and automation tools used to deploy and manage services can detect when a service crashes or becomes unresponsive and automatically restart a troubled service. Finally, a single microservice contains less code and fewer functions to test and requires far less regression testing to look for unintended consequences of changes or updates. These factors can speed up service development and maintenance.
Microservices also have challenges. As individual services proliferate, the complexity of the microservices environment multiplies. Each service depends on network performance and integrity, and every individual service must be attached to management, logging, monitoring and other tools.
Hybrid and modular application architectures
The transition from monolithic to microservices application architectures can be problematic for developers. A monolithic codebase might not parse well into tidy individual services. As an alternative, consider a hybrid microservices model, which updates a legacy application with a mix of monolithic code and services, all deployed through cloud-based containers.
Another option is a modular monolithic architecture, which seeks to balance scalability, speed and operational complexity. This approach segments code into individual feature modules, which limits dependencies and isolates data stores but preserves the simpler communications, logic encapsulation and reusability of a monolithic architecture.
Microservices architecture components and functions
Traditional applications are designed and built as a single block of code. A microservices architecture expresses an application as a series of independent but related services or software components that can be developed, tested and deployed independently, or even as separate software projects. The services interoperate and communicate through APIs across a network using lightweight protocols such as Hypertext transfer Protocol (HTTP) and Representational State Transfer (REST). Through this process, the greater application emerges.
A microservices architecture consists of several principal features or functions. In addition to individual services, typical components of a microservices architecture include APIs, containers, a service mesh, SOA concepts and the cloud.
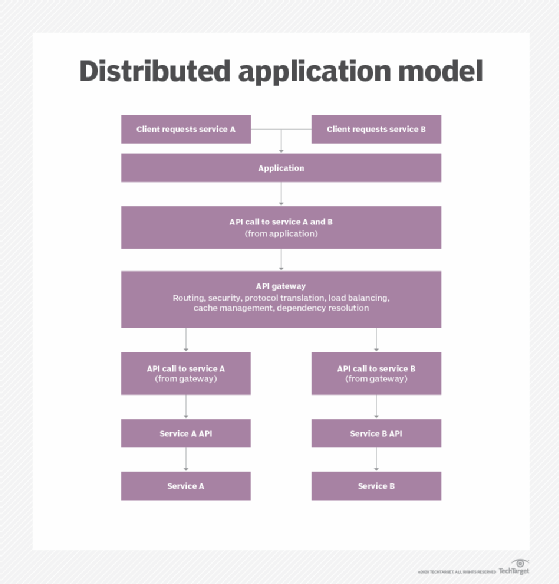
Microservices and APIs
APIs and microservices are different but complementary technologies. APIs facilitate integration and communication between various services in a microservices architecture, enabling services to request and receive results from one another. This interoperability delivers the app's overall functionality.
At the heart of this structure is an API gateway, which manages, organizes and distributes API calls between services and outside clients. Gateways also handle API security, monitoring and load balancing. Offloading such administrative overhead keeps the microservices agile and lightweight.
Microservices and containers
A container is an individual and executable package of software, including all the dependencies required to function independently. Containers are separated from the rest of the software surrounding them, and many containers can be employed in the same environment. In a microservices architecture, each service is individually containerized under the same environment, such as the same or related servers.
Microservices are almost always associated with virtual containers, which are constructs used to package services and their dependencies. Containers can share a common OS kernel that enables them to exist on servers in far greater numbers compared to more traditional virtual machines (VMs). Containers can also be quickly spun up and torn down, often within seconds.
Although containers aren't required for microservices, they make microservices practical. Containers' small and resource-lean instances are suited to the small codebases found in microservices. Their fast creation and teardown make them scalable and temporary or ethereal. Modern container orchestration tools, such as Kubernetes, support the ability to detect and restart failed containers with minimal human intervention.
By comparison, a typical VM requires an entire OS, drivers and other elements. A microservice can be deployed in a VM. This can provide extra isolation, but it also creates unnecessary redundancy and costs. Why deploy and pay for 10 to 20 OS licenses for VMs to create a single application? VMs are far more cost- and resource-efficient for complete monolithic applications.
Microservices and service mesh
Although APIs act as the proverbial glue for communication between services, the actual logic that governs communication is another challenge. It's possible, albeit cumbersome, to code communication logic into each service in a typically complex application.
On the other hand, microservices architecture often relies on a service mesh to abstract service-to-service communication away from services and into another layer of the infrastructure. It creates proxy containers -- also called sidecar containers -- that relate to one or more services and route traffic as necessary, while those services continue their operations. A microservices application can call upon numerous proxies to handle various services or collections of related services.
Microservices and SOA
There are similarities between microservices and service-oriented architecture but they aren't the same. SOA is a software development approach focused on combining reusable software components or services. A common interface lets the services interoperate across an enterprise service bus, yet requires little knowledge of how each service works. SOA components often rely on Extensible Markup Language (XML) and Simple Object Access Protocol (SOAP) to communicate.
The SOA model works best for services that are largely transactional and reusable across large software systems. SOA isn't as well suited for new or refactored code, or projects that involve rapid and continuous development and deployment cycles -- that's where microservices shine.
In some ways, microservices are an evolution of SOA, but they aren't mutually dependent. The primary difference between SOA and microservices is scope: SOA is designed to operate across the entire enterprise, while microservices' scope is confined to the application itself. SOA can complement microservices by letting applications and components interoperate with other reusable services across an enterprise.
Microservices and the cloud
Containers and microservices can be deployed and orchestrated in any data center or colocation facility, but they require an infrastructure designed to handle such volumes of integrated services, and rapid or unpredictable scaling. Public clouds provide ideal environments for on-demand and scalable computing, as well as orchestration engines, API gateways, pay-as-you-go licensing structures and other elements that act as building blocks for a microservices architecture.
Challenges of a microservices architecture
Although microservices benefits are compelling, adopters must also evaluate and address some potential disadvantages of a microservices application.
- Unnecessary complexity. Not all applications are suited for a microservices paradigm. The investment needed to apply microservices techniques to smaller and simpler applications might not yield worthwhile benefits. Consider the nature, complexity and scope of each project and evaluate the pros and cons of a microservices approach before making that design commitment.
- Performance. A microservice container provides excellent computing performance for its task, but many of them must communicate across the network for the overall application to function. Network congestion and latency can hamper performance and undo those individual performance benefits. In addition, the volume of microservices to support applications needs additional network management and control and can require multiple load-balancing instances.
- Network limitations. Microservices components rely on API-driven communication over a network. This can place significant stress on existing corporate networks in terms of bandwidth and latency -- which can be further multiplied by numerous microservices applications all working simultaneously across the corporate environment and infrastructure. Some microservices adopters might require network upgrades to support the communication demands of busy microservices applications. Further, network vulnerabilities and security risks can easily be exacerbated in complex microservices environments.
- Monitoring. A microservices application environment can be extremely complex, and all the components deployed to construct the application must be monitored and reported. This challenge is exacerbated by the ethereal nature of those components, which must be monitored as they are deployed and removed. This requires a high level of health and performance monitoring, as well as automation and orchestration.
- Security. Application security is vital to protect access to the software and underlying data, but security can be more difficult with microservices. APIs must authorize and authenticate with every call, and each component must harden the service against intrusion. Security tools and processes must monitor and report in a complex and changeable microservices environment. Extensive automation is needed to attach security configuration and monitoring to each microservices component. Further, each component module must receive suitable patches and updates to maintain consistent security across the application -- which can be difficult when modules are maintained by different teams on different schedules.
- Culture. Microservices development represents a new mindset on how to design, build and operate enterprise applications. This means a business must adjust not only the developer tools and processes they use, but also foster programming skills and team culture to support microservices. Developers must collaborate as they work on different services, and embrace continuous development paradigms, comprehensive process and workflow automation practices and monitoring and security.

The role of microservices in DevOps
Although microservices and DevOps are two different concepts and don't rely on one another, they are frequently encountered together because of the close natural alignment between the two ideas.
DevOps combines tasks between application and system operations teams. Increased communications between developers and operations staff enables an IT team to better create and manage infrastructure. DevOps project budgets frequently include provisions for deployment, capacity planning and scaling, operational tasks, upgrades and more. Developers and application teams can manage databases, servers, software and hardware used in production.
Microservices is a paradigm used to design, build and deploy modern software. This involves the creation, deployment, monitoring and management of many individual components that comprise the greater application. Because DevOps and other agile techniques are often employed to build and deploy software, the many components involved in microservices would be a natural fit for DevOps. Further, microservices lifecycle support requires teamwork and collaboration between development and operations teams, which lends itself to how DevOps teams operate. Experienced DevOps teams are well-equipped to employ microservices-type architectures in software development projects.
Design considerations for a successful microservices transition
Many microservices implementations still adhere to, and are hampered by, legacy design patterns. This means that architects and developers must adopt new design principles and patterns, consider the implications of database access and networking implications and implement efficient messaging between services. It's a tall order that takes time and experience to deliver.
Design principles
Microservices architecture design principles help streamline the operation of each service and ensure each service delivers optimum results for the overall application. The most common of these include the following principles:
- High cohesion. Services should work together with minimum communication to make the most of limited network bandwidth.
- Low coupling. Services should have few, if any, interdependencies. This minimizes the effect of disruptions should one component fail and lends itself well to reusable module design.
- Single responsibility scope. A service should set boundaries to reflect a specific business requirement and do only one thing. This furthers the idea of reusable components.
- Reliability. Design the services for maximum fault tolerance or resilience so a fault in one service doesn't disable the entire application. This often includes the use of multiple or redundant services so that a failure in one component doesn't cripple the overall application.
- Don't share data. Shared storage and data is an unwanted dependency. Each service should have or be able to access its own database or storage volume.
- Use automation. Use automation tools such as Kubernetes to deploy and manage microservices components, often as part of a CI/CD pipeline.
- Use APIs. APIs are the go-to method for interaction and communication between services. Good API design and management are essential for successful microservices applications.
- Monitor. Use monitoring tools to oversee and report the health, performance and problems with services and to manage traffic for best service performance.
Behavioral patterns
Resiliency, integration, discovery and registration are challenges for any application architecture, but especially with microservices. The following are some common microservices architectural design patterns to address:
- Discovery design. Endpoint clients that access a microservices application use client- or server-side discovery to find an available service and forward a request.
- Registration design. Services employ self-registration or third-party registration to help keep track of which services are busy and which are available.
- Flow design. Architects and developers dictate the workflow between the front-end UI and the back-end data through Model-View-Controller or Model-View-ViewModel design patterns.
- Saga design. Some microservices rely on process instructions and others perform actual functions, which enables more orderly messaging and reliable recovery.
- Reliability design. Developers allow multiple call attempts (retry) or stop communication with a failed service (circuit breaker) to prevent errors from cascading between services.
- Transitional design. Refactor a monolithic application into microservices, such as through a strangler design pattern, to help segment a legacy application into specific functions and create decoupled modules. In some cases, this requires a fundamental redesign of the legacy application to accommodate microservices practices.
Database implications
Data management for microservices isn't simply a matter of design or technology, but rather a set of attributes or principles that support consistency, scaling and resilience for microservices applications. Fundamental microservices design patterns include the following:
- Single database per service. When correlating a service to a database, assign only one database to the service.
- Shared database. If multiple services share a database, concurrency demands can potentially cause conflicts; a nontraditional database, such as NoSQL, can reduce contention but isn't appropriate for many types of data.
- Saga design. Create a series of transactions and confirmations that lets the database back out of a transaction and alert the system that an error has occurred.
- Event-based design. Employ a static database to capture and store records of event-based transactions.
Messaging patterns
Communication between services can pose challenges for developers and architects. Consider the following microservices messaging approaches:
- Loose vs. tight coupling. Loosely coupled services reduce dependencies but often demand more frequent and comprehensive messaging, while tightly coupled services can require less communication but carry more dependencies.
- Asynchronous vs. synchronous communication. A single channel and a request/response style is common in monolithic applications, but multiple and one-to-many communication channels are more efficient -- even essential -- for some microservices applications.
- Message brokers. Lightweight message brokers, such as Amazon Simple Notification Service, can handle and sort messaging without waiting for responses, and are a common approach in complex microservices applications. Designers can choose from numerous messaging tools and platforms for microservices applications.
Key steps to deploy microservices
There are two general rules for any microservices project: A distributed microservices architecture isn't right for every enterprise or application type, and there is no single universal plan to deploy microservices in production. There are simply too many potential choices and alternatives available for developers and operations staff. Follow these guidelines to help smooth a microservices deployment and help avoid common microservices pitfalls.
1. Use the cloud. Using microservices in a containerized infrastructure in a traditional data center can make sense for certain limited deployments. But the public cloud's scalability, on-demand resources and native orchestration services make it an efficient and cost-effective infrastructure for container-based microservices.
2. Emphasize resilience. Create microservices as stateless entities that can be stopped, restarted, patched and scaled -- all without disrupting other services or the overall application. Designs that allow excessive dependencies, such as shared data stores, between services can turn a planned microservices architecture into a distributed monolithic one.
3. Decentralize data. Each individual service should access its own data resources to ensure it has the data it needs and to prevent data inconsistencies. Services also can use the best database design for the task at hand, and changes to one database and data store won't affect other services.
4. Eliminate silos. Traditional applications often employ IT groups organized into silos that handle specific parts of the application's deployment. Microservices are better served through cross-functional and highly collaborative teams organized around the microservices application. This demands a flexible and supportive culture, such as DevOps or other agile paradigms, to find and fix problems as quickly and efficiently as possible.
5. Automate everywhere. Modern application development uses tightly coupled pipelines to build, test and deploy software -- and microservices are suited to pipelines. The same automation frameworks that drive building and testing can be extended to deployments, which speeds the release of new updated services to production, as well as troubleshooting and fixing problems by efficiently restarting services.
6. Use monitoring. An unmonitored service can't be managed. Use monitoring tools suited to dynamic component environments for every service in complex microservices environments. Deployment automation helps ensure each component is properly connected to associated monitoring, logging and reporting tools that can track component health and performance.

7. Combine and centralize logs. Microservices logging often involves separate logs for each service. However, data in log files stored in individual containers are lost when the container is destroyed and can be difficult or impossible to find. Store logs in persistent storage. Consider data consistency and synchronization when creating many logs so that it's possible to combine them and form a cohesive picture of activity when trouble strikes. Log analytics tools can be a worthwhile investment for microservices applications.
8. Embrace security. Microservices architectures are sensitive to security issues. Large numbers of services, API dependence, disaggregated log files and extensive network communication requirements create a large attack surface with multiple attack vectors. Some microservices security best practices include the following:
- Using multiple layers of security. A single security tool or framework is rarely adequate to mitigate all security risks. Use all security measures available -- firewalls, tokens, encryption and monitoring -- to secure services and the overall application.
- Focusing on access security. Encrypt any data accessed and exchanged between services, and secure APIs with proper authentication and authorization that adheres to least-privilege principles.
- Communicating and collaborating. Developers and operations staff must work together with security groups to create a comprehensive security approach and environment, a concept known as DevSecOps.
9. Extend testing. The complexity of microservices architectures extends to testing them. Typical application end-to-end testing is less than ideal for microservices, so explore other options. Test services as individual subsystems, with cloning or simulation to handle any dependencies or related services. Contract testing scans how software under test uses an API, and then creates tests based on that usage. How one deploys microservices also affects the testing. Rather than a sweeping deployment or update, each microservice can be deployed, updated, patched, tested and managed separately from other services. Prepare rigorous tests and strong rollback plans in case trouble arises. Consider testing cloud-based microservices locally; with sufficient service isolation, tests on one service won't affect others.
10. Adopt versioning techniques. Microservices adoption demands proper version control to ensure the overall application includes the correct array of services, some or all of which can be updated and maintained independently by different teams on different schedules. Even microservices that are independent and loosely coupled can have dependencies. A change in one version can require changes to other services, which results in corresponding version changes to other services. Microservices versioning techniques include the following approaches:
- Uniform Resource Identifier (URI) versioning.
- Header versioning.
- Semantic versioning.
- Calendar versioning.
Tools to deploy and manage microservices
Thanks to synergy with APIs, containers and continuous development processes, microservices can use many of the same tools for design, test, deployment and management.
Kubernetes is the de facto standard for container-based orchestration, whether an enterprise uses this in its own local environments or through a cloud-based service. Other orchestration tools include Docker Swarm and Compose, and HashiCorp Nomad.
Organizations can choose from a wide range of other tools that span testing, deployment, monitoring and management of microservices environments. Examples of tools that span areas of testing include Gatling, Hoverfly, Jaeger, Pact, Vagrant, VCR and WireMock. API management tools include API Fortress, Postman and Tyk. Architectural frameworks tools well-suited for microservices and REST APIs include Goa and Kong.
Microservices monitoring and management can be particularly challenging, given the need to track and maintain each service component of an application and their interactions. These functions include observability, failure detection and gathering metrics from logs to identify performance and stability issues. Examples of monitoring tools include Sentry, Sensu and Sumo Logic. Some examples of log aggregation tools include Fluentd, Logstash, Ryslog and Loggly. For log visualization, tools include Scalyr, Graylog, Kibana and Sematext.
Service mesh is a layer of infrastructure dedicated to communication between individual services. When hundreds of services communicate with each other, it becomes complicated to determine what services are interacting with each other. A service mesh, such as Linkerd and Istio, makes those communications faster, more secure, visible and reliable by capturing behaviors such as latency-aware load balancing or service discovery. Major cloud providers offer ancillary services to help manage microservices.
Improvements in these technologies, and others such as intricate monitoring and logging, have reduced microservices complexity and spurred continued adoption by organizations and development teams.